yipeiwu_com6年前
在上篇文章给大家分享PHP源码批量抓取远程网页图片并保存到本地的实现方法,感兴趣的朋友可以点击了解详情。 #-*-coding:utf-8-*- import os import...
yipeiwu_com6年前
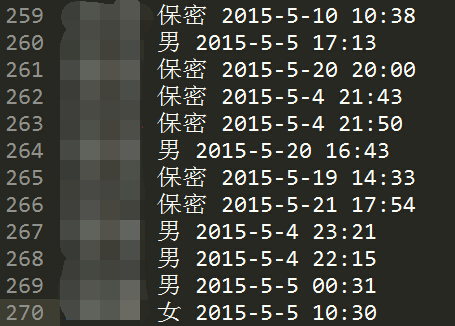
一、项目需求 前言:BBS上每个id对应一个用户,他们注册时候会填写性别(男、女、保密三选一)。 经过检查,BBS注册用户的id对应1-300000,大概是30万的用户 笔者想用Pyth...
yipeiwu_com6年前
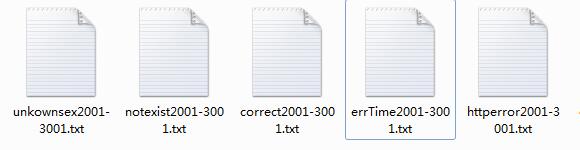
接着第一篇继续学习。 一、数据分类 正确数据:id、性别、活动时间三者都有 放在这个文件里file1 = 'ruisi\\correct%s-%s.txt' % (startNum, e...
yipeiwu_com6年前
本文主要介绍了数据处理方面的内容,希望大家仔细阅读。 一、数据分析 得到了以下列字符串开头的文本数据,我们需要进行处理 二、回滚 我们需要对httperror的数据进行再处理 因为代...
yipeiwu_com6年前
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或...
yipeiwu_com6年前
什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来...
yipeiwu_com6年前
urllib 学习python完基础,有些迷茫.眼睛一闭,一种空白的窒息源源不断而来.还是缺少练习,遂拿爬虫来练练手.学习完斯巴达python爬虫课程后,将心得整理如下,供后续翻看.整篇...
yipeiwu_com6年前
1.安装BeautifulSoup4 easy_install安装方式,easy_install需要提前安装 easy_install beautifulsoup4 pip安装方...
yipeiwu_com6年前
抓取豆瓣电影TOP100 一、分析豆瓣top页面,构建程序结构 1.首先打开网页http://movie.douban.com/top250?start,也就是top页面 然后试...
yipeiwu_com6年前
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页...