yipeiwu_com6年前
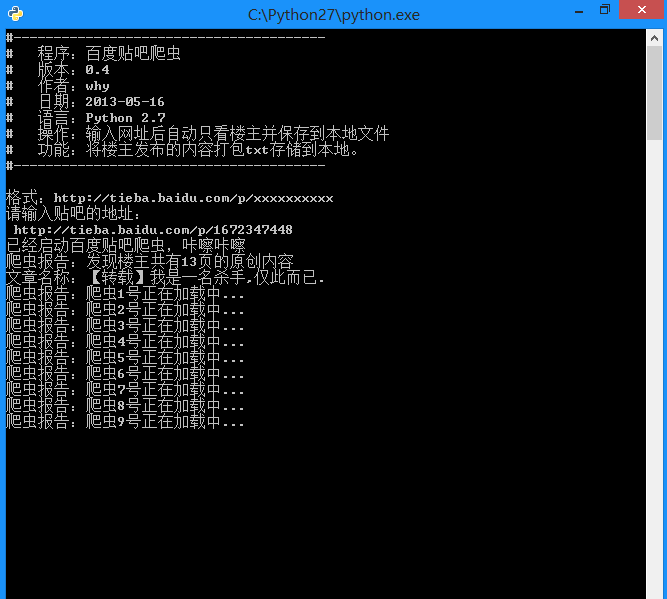
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件。 项目内容: 用Python写的百度贴吧的网络爬虫。 使用方法: 新建一...
yipeiwu_com6年前
1.下载pyinstaller并解压(可以去官网下载最新版): https://github.com/pyinstaller/pyinstaller/ 2.下载pywin32并安装(注意...
yipeiwu_com6年前
先来说一下我们学校的网站: http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html 查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没...
yipeiwu_com6年前
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下。 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点。...
yipeiwu_com6年前
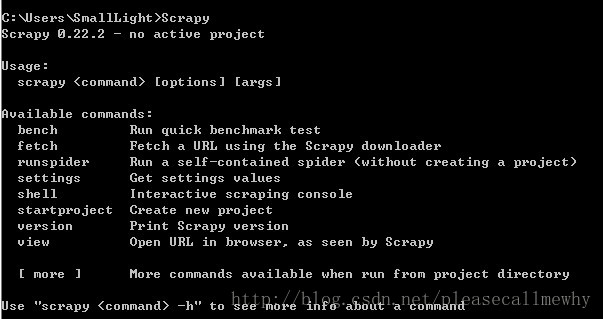
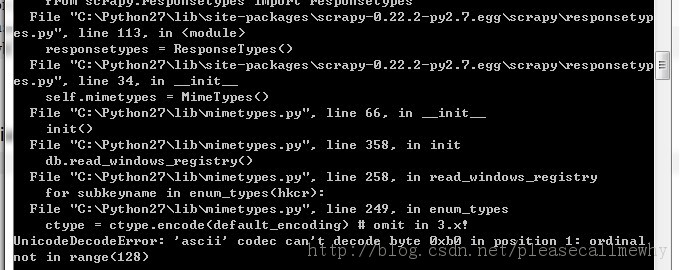
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据。虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。Scrapy是一个使用Pyth...
yipeiwu_com6年前
用Python实现常规的静态网页抓取时,往往是用urllib2来获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字。如下所示: 复制代码 代码如下: import urlli...
yipeiwu_com6年前
写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品。 从网页http://mm.taobao.com/json/request_top_list.h...
yipeiwu_com6年前
除了C/C++以外,我也接触过不少流行的语言,PHP、java、javascript、python,其中python可以说是操作起来最方便,缺点最少的语言了。 前几天想写爬虫,后来跟朋友...
yipeiwu_com6年前
比如,你想采集标题中包含“58同城”的SERP结果,并过滤包含有“北京”或“厦门”等结果数据。 该Python脚本主要是实现以上功能。 其中,使用BeautifulSoup来解析HTM...
yipeiwu_com6年前
学了下beautifulsoup后,做个个网络爬虫,爬取读者杂志并用reportlab制作成pdf.. crawler.py 复制代码 代码如下: #!/usr/bin/env pyth...