python写的一个squid访问日志分析的小程序
这两周组里面几位想学习python,于是我们就创建了一个这样的环境和氛围来给大家学习。
昨天在群里,贴了一个需求,就是统计squid访问日志中ip 访问数和url的访问数并排序,不少同学都大体实现了相应的功能,我把我简单实现的贴出来,欢迎拍砖:
日志格式如下:
复制代码 代码如下:
%ts.%03tu %6tr %{X-Forwarded-For}>h %Ss/%03Hs %<st %rm %ru %un %Sh/%<A %mt "%{Referer}>h" "%{User-Agent}>h" %{Cookie}>h
复制代码 代码如下:
1372776321.285 0 100.64.19.225 TCP_HIT/200 8560 GET http://img1.jb51.net/games/0908/19/1549401_3_80x100.jpg - NONE/- image/jpeg "//www.jb51.net/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; QQDownload 734; .NET4.0C; .NET CLR 2.0.50727)" pcsuv=0;%20pcuvdata=lastAccessTime=1372776317582;%20u4ad=33480hn;%20c=14arynt;%20uf=1372776310453
复制代码 代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
from optparse import OptionParser
'''
仅仅是一个关于日志文件的测试,统计处access.log 的ip数目
'''
try:
f = open('/data/proclog/log/squid/access.log')
except IOError,e:
print "can't open the file:%s" %(e)
def log_report(field):
'''
return the field of the access log
'''
if field == "ip":
return [line.split()[2] for line in f]
if field == "url":
return [line.split()[6] for line in f]
def log_count(field):
'''
return a dict of like {field:number}
'''
fields2 = {}
fields = log_report(field)
for field_tmp in fields:
if field_tmp in fields2:
fields2[field_tmp] += 1
else:
fields2[field_tmp] = 1
return fields2
def log_sort(field,number = 10 ,reverse = True):
'''
print the sorted fields to output
'''
for v in sorted(log_count(field).iteritems(),key = lambda x:x[1] , reverse = reverse )[0:int(number)]:
print v[1],v[0]
if __name__ == "__main__":
parser =OptionParser(usage="%prog [-i|-u] [-n num | -r]" ,version = "1.0")
parser.add_option('-n','--number',dest="number",type=int,default=10,help=" print top line of the ouput")
parser.add_option('-i','--ip',dest="ip",action = "store_true",help="print ip information of access log")
parser.add_option('-u','--url',dest="url",action = "store_true",help="print url information of access log")
parser.add_option('-r','--reverse',action = "store_true",dest="reverse",help="reverse output ")
(options,args) = parser.parse_args()
if len(sys.argv) < 2:
parser.print_help()
if options.ip and options.url:
parser.error(' -i and -u can not be execute at the same time ')
if options.ip :
log_sort("ip", options.number , True and options.reverse or False)
if options.url:
log_sort("url", options.number , True and options.reverse or False)
f.close()
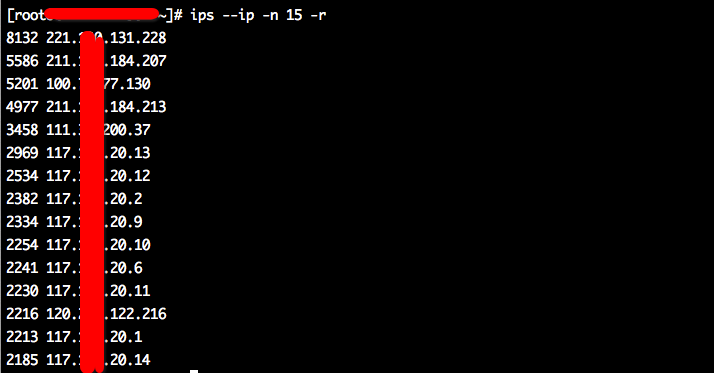
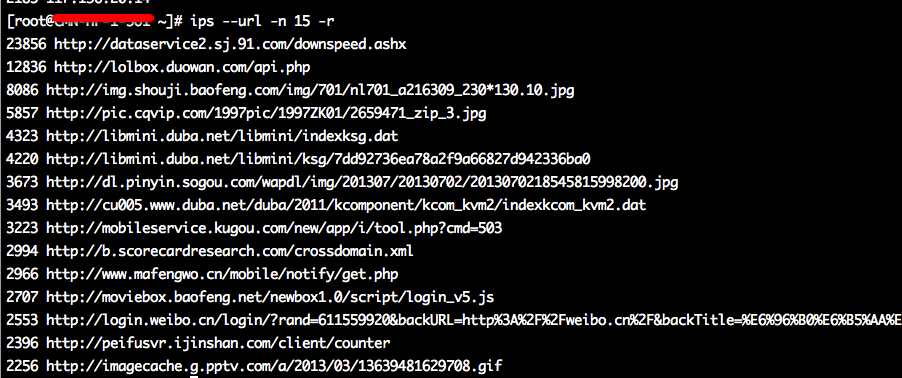
效果如下: