Python2.x中文乱码问题解决方法
Python中乱码问题是一个很头痛的问题。
在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文。否则会出现乱码
【问题原因】
在Python2.x中主要是字符编码的问题,处理不好的话,会导致乱码。Python默认采取的ASCII编码,字母、标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求。
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
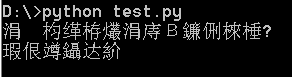
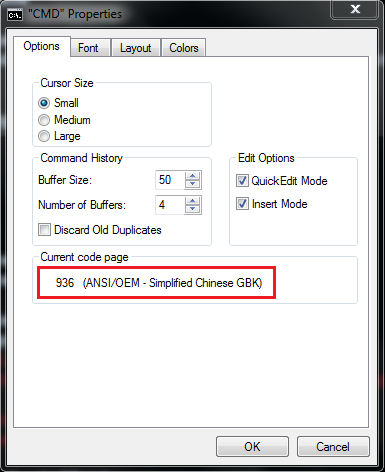
为了能在计算机中表示所有的中文字符,中文编码采用两个字节表示。如果中文编码和ASCII混合使用的话,就会导致解码错误,从而才生乱码。而CMD下默认的编码方式为:GBK,所以就造成了上面的乱码!
采用两个字节的中文编码标准有:GB2312、GBK、BIG5等。
【处理办法】
为了将各种不同的语言包含在统一的字符集中,满足国际间的信息交流,国际上制订了UNICODE字符集,包含了世界上所有语言字符,这些字符具有唯一的编码,通过使用UNICODE字符集可以满足跨语言的文字处理,避免乱码的产生。
i) 交互式命令中:一般不会出现乱码,无需做处理

ii) py脚本文件中:跨字符集必须做设置,否则乱码。
首先在开头一句添加:
# coding = utf-8
# 或
# coding = UTF-8
# 或
# -*- coding: utf-8 -*-
其次需将文件保存为UTF-8的格式!
上面那一句仅仅是告诉Python编译器:脚本中包含了非ASCII字符,并未进行转换。
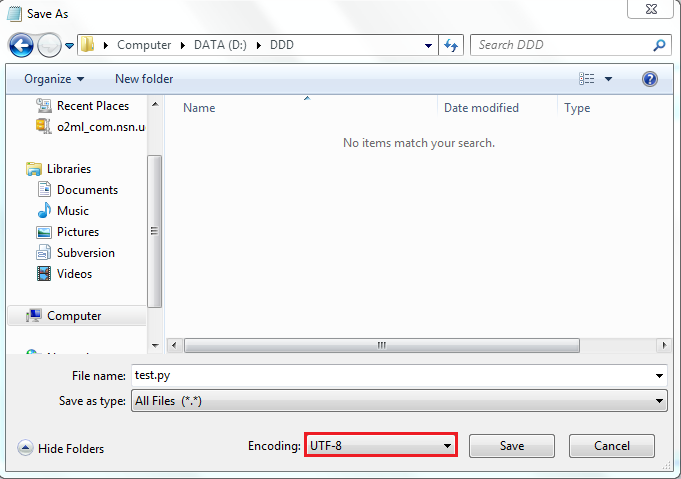
如果要将字符编码从默认的ASCII改为UTF-8,需要在保存的时候选择保存为UTF-8格式。
如果是用NODEPAD打开,【另存为】-->UTF-8即可
如果是用IDLE打开,【Options】-> 【Configure IDLE】->【General】
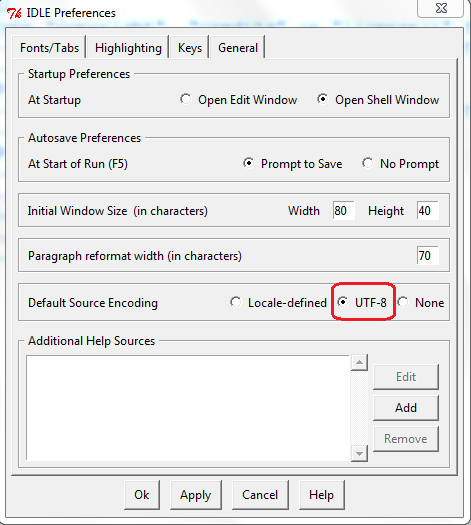
上面的设置,可以保证IDLE,运行F5,能正常输出中文。
【编码解码】
在开头添加了# -*- coding: utf-8 -*-并将文件保存为UTF-8格式,仍然不能保证能输出正常输出中文,
不同的编辑器,如VIM,IDLE,Eclipse使用的输出编码都是不一致的。
所以,在一个地方能正常输出中文,在另外一个地方就未必。所以还必须做编码解码设置!
encode:编码
decode:解码
必须保证编码、解码的对象是同一个。比如说UTF-8方式编码, 必须再用UTF-8进行解码即可。
所以最终解决办法,还必须先按原先的方式解码,再按控制台格式重新编码:比如CMD默认是GBK方式
则必须使用如下方式:

正确输出结果:

【其他说明】
1.在Python3中,对中文的支持非常全面,源文件默认保存为UTF-8的编码,这样一来,不但可以在源代码中使用中文,而且变量名也可以使用中文,比如说:
>>> 中国 = 'Chinese'
>>> print(中国)
Chinese
2.在Python3中,不需要来回的编解码,并且字符串对象也没有decode和encode方法。