Python实现简单多线程任务队列
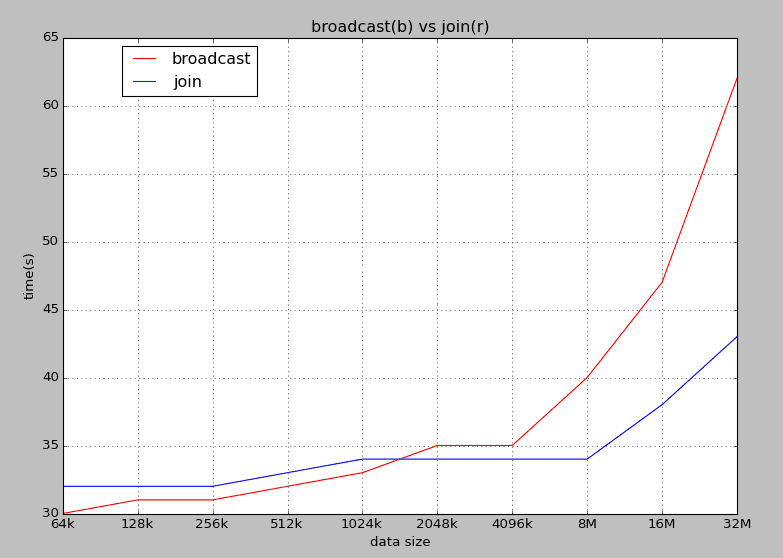
最近我在用梯度下降算法绘制神经网络的数据时,遇到了一些算法性能的问题。梯度下降算法的代码如下(伪代码):
def gradient_descent(): # the gradient descent code plotly.write(X, Y)
一般来说,当网络请求 plot.ly 绘图时会阻塞等待返回,于是也会影响到其他的梯度下降函数的执行速度。
一种解决办法是每调用一次 plotly.write 函数就开启一个新的线程,但是这种方法感觉不是很好。 我不想用一个像 cerely(一种分布式任务队列)一样大而全的任务队列框架,因为框架对于我的这点需求来说太重了,并且我的绘图也并不需要 redis 来持久化数据。
那用什么办法解决呢?我在 python 中写了一个很小的任务队列,它可以在一个单独的线程中调用 plotly.write函数。下面是程序代码。
from threading import Thread import Queue import time class TaskQueue(Queue.Queue):
首先我们继承 Queue.Queue 类。从 Queue.Queue 类可以继承 get 和 put 方法,以及队列的行为。
def __init__(self, num_workers=1): Queue.Queue.__init__(self) self.num_workers = num_workers self.start_workers()
初始化的时候,我们可以不用考虑工作线程的数量。
def add_task(self, task, *args, **kwargs):
args = args or ()
kwargs = kwargs or {}
self.put((task, args, kwargs))
我们把 task, args, kwargs 以元组的形式存储在队列中。*args 可以传递数量不等的参数,**kwargs 可以传递命名参数。
def start_workers(self):
for i in range(self.num_workers):
t = Thread(target=self.worker)
t.daemon = True
t.start()
我们为每个 worker 创建一个线程,然后在后台删除。
下面是 worker 函数的代码:
def worker(self):
while True:
tupl = self.get()
item, args, kwargs = self.get()
item(*args, **kwargs)
self.task_done()
worker 函数获取队列顶端的任务,并根据输入参数运行,除此之外,没有其他的功能。下面是队列的代码:
我们可以通过下面的代码测试:
def blokkah(*args, **kwargs): time.sleep(5) print “Blokkah mofo!” q = TaskQueue(num_workers=5) for item in range(1): q.add_task(blokkah) q.join() # wait for all the tasks to finish. print “All done!”
Blokkah 是我们要做的任务名称。队列已经缓存在内存中,并且没有执行很多任务。下面的步骤是把主队列当做单独的进程来运行,这样主程序退出以及执行数据库持久化时,队列任务不会停止运行。但是这个例子很好地展示了如何从一个很简单的小任务写成像工作队列这样复杂的程序。
def gradient_descent(): # the gradient descent code queue.add_task(plotly.write, x=X, y=Y)
修改之后,我的梯度下降算法工作效率似乎更高了。如果你很感兴趣的话,可以参考下面的代码。
from threading import Thread
import Queue
import time
class TaskQueue(Queue.Queue):
def __init__(self, num_workers=1):
Queue.Queue.__init__(self)
self.num_workers = num_workers
self.start_workers()
def add_task(self, task, *args, **kwargs):
args = args or ()
kwargs = kwargs or {}
self.put((task, args, kwargs))
def start_workers(self):
for i in range(self.num_workers):
t = Thread(target=self.worker)
t.daemon = True
t.start()
def worker(self):
while True:
tupl = self.get()
item, args, kwargs = self.get()
item(*args, **kwargs)
self.task_done()
def tests():
def blokkah(*args, **kwargs):
time.sleep(5)
print "Blokkah mofo!"
q = TaskQueue(num_workers=5)
for item in range(10):
q.add_task(blokkah)
q.join() # block until all tasks are done
print "All done!"
if __name__ == "__main__":
tests()