完美解决Python2操作中文名文件乱码的问题
Python2默认是不支持中文的,一般我们在程序的开头加上#-*-coding:utf-8-*-来解决这个问题,但是在我用open()方法打开文件时,中文名字却显示成了乱码。
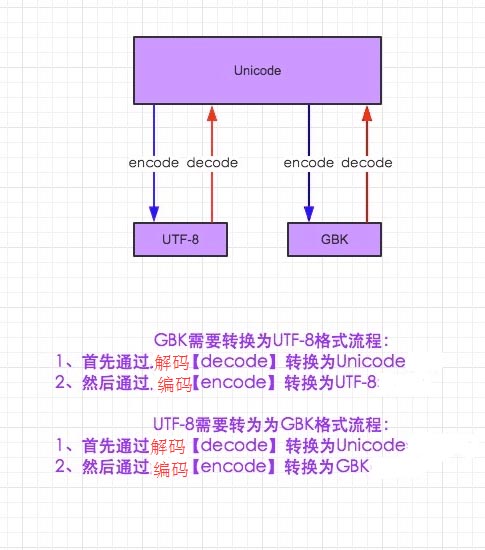
我先给大家说说Python中的编码问题,Python中的字符串的大概分为为str和Unicode两种形式,其中str常用的编码类型为utf-8,gb2312,gbk等等,Python使用Unicode作为编码的基础类型。str记录的是字节数组,只是某种编码的存储格式,终于输出到文件或是打印出来是什么格式,完全取决于其解码的编码将他解码成什么样子;Unicode是一种类似于符号集的抽象编码,它只规定了符号的二进制代码,却没有规定这个二进制代码该如何存储,也就是它只是一种内部表示,不能直接保存,所以存储时需要规定一种存储形式,比如utf-8等。
Python中有编码转换的函数有:
decode(char_set) 实现char_set解码成Unicodeencode(char_set) 实现Unicode编码成char_set
查看Python文档会发现:
open(filename, 'w')这个方法中,filename这个参数必须是Unicode编码的参数。
我之前加上#-*-coding:utf-8-*-将编码设置为utf-8,当调用这个方法往里传参数时,需要将这个变量filename解码成Unicode。
比如filename='中文.txt',使用open()时,这样写open(filename.decode('utf-8'), 'w'),这样创建的中文文件名就没有乱码问题了。
以上就是小编为大家带来的完美解决Python2操作中文名文件乱码的问题全部内容了,希望大家多多支持【听图阁-专注于Python设计】~