Python实现句子翻译功能
初入Python,一开始就被她简介的语法所吸引,代码简洁优雅,之前在C#里面打开文件写入文件等操作相比Python复杂多了,而Python打开、修改和保存文件显得简单得多。
1、打开文件的例子:
file=open('D:\\Python\\untitled\\Hello.txt','r',encoding='utf-8')
data=file.read()
print(data)
file.close()
2、利用urllib库请求页面进行简单的翻译,请求百度翻译,将要翻译的内容当做参数传给百度,然后将结果赋值给参数,最后打印出来:
上代码:
import urllib.request
import urllib.parse
import json
content=input("=====请输入您要翻译的内容:=====\n")
url='http://fanyi.baidu.com/v2transapi'
data={}
data['from']='zh'
data['to']='en'
data['transtype']='translang'
data['simple_means_flag']='3'
data['query']=content
data=urllib.parse.urlencode(data).encode('utf-8')
response=urllib.request.urlopen(url,data)
html=response.read().decode('utf-8')
target=json.loads(html)
print("翻译结果为:%s"%(target['trans_result']['data'][0]['dst']))
实现效果如图:
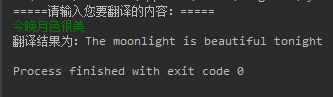
实现代码很简单,下面再分享下urllib库的一些用法。
urlopen 语法
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None) #url:访问的网址 #data:额外的数据,如header,form data
用法
# request:GET
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
# request: POST
# http测试:http://httpbin.org/
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read())
# 超时设置
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(response.read())
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')
响应
# 响应类型
import urllib.open
response = urllib.request.urlopen('https:///www.python.org')
print(type(response))
# 状态码, 响应头
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))
Request
声明一个request对象,该对象可以包括header等信息,然后用urlopen打开。
# 简单例子
import urllib.request
request = urllib.request.Requests('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
# 增加header
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
'Host':'httpbin.org'
}
# 构造POST表格
dict = {
'name':'Germey'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url=url,data=data,headers=headers,method='POST')
response = request.urlopen(req)
print(response.read()).decode('utf-8')
# 或者随后增加header
from urllib import request, parse
url = 'http://httpbin.org/post'
dict = {
'name':'Germey'
}
req = request.Request(url=url,data=data,method='POST')
req.add_hader('User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
总结
以上就是本文关于Python实现句子翻译功能的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
如有不足之处,欢迎留言指出。