python实现机械分词之逆向最大匹配算法代码示例
逆向最大匹配方法
有正即有负,正向最大匹配算法大家可以参阅/post/127404.htm
逆向最大匹配分词是中文分词基本算法之一,因为是机械切分,所以它也有分词速度快的优点,且逆向最大匹配分词比起正向最大匹配分词更符合人们的语言习惯。逆向最大匹配分词需要在已有词典的基础上,从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(分词所确定的阈值i)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。而且选择的阈值越大,分词越慢,但准确性越好。
逆向最大匹配算法python实现:
分词文本示例:

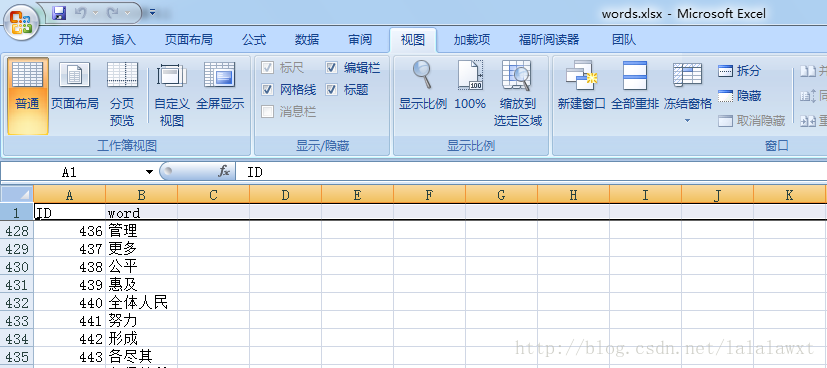
分词词典words.xlsx示例:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
'''''
用逆向最大匹配法分词,不去除停用词
'''
import codecs
import xlrd
#读取待分词文本,readlines()返回句子list
def readfile(raw_file_path):
with codecs.open(raw_file_path,"r",encoding="ANSI") as f:
raw_file=f.readlines()
return raw_file
#读取分词词典,返回分词词典list
def read_dic(dic_path):
excel = xlrd.open_workbook(dic_path)
sheet = excel.sheets()[0]
# 读取第二列的数据
data_list = list(sheet.col_values(1))[1:]
return data_list
#逆向最大匹配法分词
def cut_words(raw_sentences,word_dic):
word_cut=[]
#最大词长,分词词典中的最大词长,为初始分词的最大词长
max_length=max(len(word) for word in word_dic)
for sentence in raw_sentences:
#strip()函数返回一个没有首尾空白字符(‘\n'、‘\r'、‘\t'、‘')的sentence,避免分词错误
sentence=sentence.strip()
#单句中的字数
words_length = len(sentence)
#存储切分出的词语
cut_word_list=[]
#判断句子是否切分完毕
while words_length > 0:
max_cut_length = min(words_length, max_length)
for i in range(max_cut_length, 0, -1):
#根据切片性质,截取words_length-i到words_length-1索引的字,不包括words_length,所以不会溢出
new_word = sentence[words_length - i: words_length]
if new_word in word_dic:
cut_word_list.append(new_word)
words_length = words_length - i
break
elif i == 1:
cut_word_list.append(new_word)
words_length = words_length - 1
#因为是逆向最大匹配,所以最终需要把结果逆向输出,转换为原始顺序
cut_word_list.reverse()
words="/".join(cut_word_list)
#最终把句子首端的分词符号删除,是避免以后将分词结果转化为列表时会出现空字符串元素
word_cut.append(words.lstrip("/"))
return word_cut
#输出分词文本
def outfile(out_path,sentences):
#输出模式是“a”即在原始文本上继续追加文本
with codecs.open(out_path,"a","utf8") as f:
for sentence in sentences:
f.write(sentence)
print("well done!")
def main():
#读取待分词文本
rawfile_path = r"逆向分词文本.txt"
raw_file=readfile(rawfile_path)
#读取分词词典
wordfile_path = r"words.xlsx"
words_dic = read_dic(wordfile_path)
#逆向最大匹配法分词
content_cut = cut_words(raw_file,words_dic)
#输出文本
outfile_path = r"分词结果.txt"
outfile(outfile_path,content_cut)
if __name__=="__main__":
main()

总结
分析分词结果可以知道,机械分词的效果优劣,一方面与分词匹配算法有关,另外一方面极其依赖分词词典。所以若想得到好的分词效果,处理相关领域的文本时,需要在分词词典中加入特定领域的词汇。
以上就是本文关于python实现机械分词之逆向最大匹配算法代码示例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!