Python多进程multiprocessing.Pool类详解
multiprocessing模块
multiprocessing包是Python中的多进程管理包。它与 threading.Thread类似,可以利用multiprocessing.Process对象来创建一个进程。该进程可以允许放在Python程序内部编写的函数中。该Process对象与Thread对象的用法相同,拥有is_alive()、join([timeout])、run()、start()、terminate()等方法。属性有:authkey、daemon(要通过start()设置)、exitcode(进程在运行时为None、如果为–N,表示被信号N结束)、name、pid。此外multiprocessing包中也有Lock/Event/Semaphore/Condition类,用来同步进程,其用法也与threading包中的同名类一样。multiprocessing的很大一部份与threading使用同一套API,只不过换到了多进程的情境。
这个模块表示像线程一样管理进程,这个是multiprocessing的核心,它与threading很相似,对多核CPU的利用率会比threading好的多。
看一下Process类的构造方法:
__init__(self, group=None, target=None, name=None, args=(), kwargs={})
参数说明:
group:进程所属组。基本不用
target:表示调用对象。
args:表示调用对象的位置参数元组。
name:别名
kwargs:表示调用对象的字典。
创建进程的简单实例:
#coding=utf-8 import multiprocessing def do(n) : #获取当前线程的名字 name = multiprocessing.current_process().name print name,'starting' print "worker ", n return if __name__ == '__main__' : numList = [] for i in xrange(5) : p = multiprocessing.Process(target=do, args=(i,)) numList.append(p) p.start() p.join() print "Process end."
执行结果:
Process-1 starting worker 0 Process end. Process-2 starting worker 1 Process end. Process-3 starting worker 2 Process end. Process-4 starting worker 3 Process end. Process-5 starting worker 4 Process end.
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,并用其start()方法启动,这样创建进程比fork()还要简单。
join()方法表示等待子进程结束以后再继续往下运行,通常用于进程间的同步。
注意:
在Windows上要想使用进程模块,就必须把有关进程的代码写在当前.py文件的if __name__ == ‘__main__' :语句的下面,才能正常使用Windows下的进程模块。Unix/Linux下则不需要。
Pool类
在使用Python进行系统管理时,特别是同时操作多个文件目录或者远程控制多台主机,并行操作可以节约大量的时间。如果操作的对象数目不大时,还可以直接使用Process类动态的生成多个进程,十几个还好,但是如果上百个甚至更多,那手动去限制进程数量就显得特别的繁琐,此时进程池就派上用场了。
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
下面介绍一下multiprocessing 模块下的Pool类下的几个方法
apply()
函数原型:
apply(func[, args=()[, kwds={}]])
该函数用于传递不定参数,主进程会被阻塞直到函数执行结束(不建议使用,并且3.x以后不在出现)。
apply_async()
函数原型:
apply_async(func[, args=()[, kwds={}[, callback=None]]])
与apply用法一样,但它是非阻塞且支持结果返回进行回调。
map()
函数原型:
map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到返回结果。
注意,虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
close()
关闭进程池(pool),使其不在接受新的任务。
terminate()
结束工作进程,不在处理未处理的任务。
join()
主进程阻塞等待子进程的退出,join方法必须在close或terminate之后使用。
multiprocessing.Pool类的实例:
import time from multiprocessing import Pool def run(fn): #fn: 函数参数是数据列表的一个元素 time.sleep(1) return fn*fn if __name__ == "__main__": testFL = [1,2,3,4,5,6] print 'shunxu:' #顺序执行(也就是串行执行,单进程) s = time.time() for fn in testFL: run(fn) e1 = time.time() print "顺序执行时间:", int(e1 - s) print 'concurrent:' #创建多个进程,并行执行 pool = Pool(5) #创建拥有5个进程数量的进程池 #testFL:要处理的数据列表,run:处理testFL列表中数据的函数 rl =pool.map(run, testFL) pool.close()#关闭进程池,不再接受新的进程 pool.join()#主进程阻塞等待子进程的退出 e2 = time.time() print "并行执行时间:", int(e2-e1) print rl
执行结果:
shunxu:
顺序执行时间: 6
concurrent:
并行执行时间: 2
[1, 4, 9, 16, 25, 36]
上例是一个创建多个进程并发处理与顺序执行处理同一数据,所用时间的差别。从结果可以看出,并发执行的时间明显比顺序执行要快很多,但是进程是要耗资源的,所以平时工作中,进程数也不能开太大。
程序中的r1表示全部进程执行结束后全局的返回结果集,run函数有返回值,所以一个进程对应一个返回结果,这个结果存在一个列表中,也就是一个结果堆中,实际上是用了队列的原理,等待所有进程都执行完毕,就返回这个列表(列表的顺序不定)。
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),让其不再接受新的Process了。
再看一个实例:
import time from multiprocessing import Pool def run(fn) : time.sleep(2) print fn if __name__ == "__main__" : startTime = time.time() testFL = [1,2,3,4,5] pool = Pool(10)#可以同时跑10个进程 pool.map(run,testFL) pool.close() pool.join() endTime = time.time() print "time :", endTime - startTime
执行结果:
21 3 4 5 time : 2.51999998093
再次执行结果如下:
1 34 2 5 time : 2.48600006104
结果中为什么还有空行和没有折行的数据呢?其实这跟进程调度有关,当有多个进程并行执行时,每个进程得到的时间片时间不一样,哪个进程接受哪个请求以及执行完成时间都是不定的,所以会出现输出乱序的情况。那为什么又会有没这行和空行的情况呢?因为有可能在执行第一个进程时,刚要打印换行符时,切换到另一个进程,这样就极有可能两个数字打印到同一行,并且再次切换回第一个进程时会打印一个换行符,所以就会出现空行的情况。
进程实战实例
并行处理某个目录下文件中的字符个数和行数,存入res.txt文件中,
每个文件一行,格式为:filename:lineNumber,charNumber
import os
import time
from multiprocessing import Pool
def getFile(path) :
#获取目录下的文件list
fileList = []
for root, dirs, files in list(os.walk(path)) :
for i in files :
if i.endswith('.txt') or i.endswith('.10w') :
fileList.append(root + "\\" + i)
return fileList
def operFile(filePath) :
#统计每个文件中行数和字符数,并返回
filePath = filePath
fp = open(filePath)
content = fp.readlines()
fp.close()
lines = len(content)
alphaNum = 0
for i in content :
alphaNum += len(i.strip('\n'))
return lines,alphaNum,filePath
def out(list1, writeFilePath) :
#将统计结果写入结果文件中
fileLines = 0
charNum = 0
fp = open(writeFilePath,'a')
for i in list1 :
fp.write(i[2] + " 行数:"+ str(i[0]) + " 字符数:"+str(i[1]) + "\n")
fileLines += i[0]
charNum += i[1]
fp.close()
print fileLines, charNum
if __name__ == "__main__":
#创建多个进程去统计目录中所有文件的行数和字符数
startTime = time.time()
filePath = "C:\\wcx\\a"
fileList = getFile(filePath)
pool = Pool(5)
resultList =pool.map(operFile, fileList)
pool.close()
pool.join()
writeFilePath = "c:\\wcx\\res.txt"
print resultList
out(resultList, writeFilePath)
endTime = time.time()
print "used time is ", endTime - startTime
执行结果:
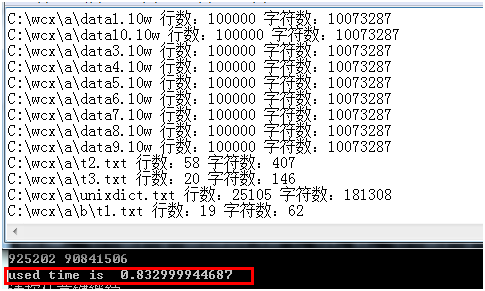
耗时不到1秒,可见多进程并发执行速度是很快的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
