python实现扫描日志关键字的示例
我们在压力测试过程会收集到很多log,怎样快速从中找到有用信息呢?让python脚本帮我们做这部分工作吧!
废话不说,上代码
环境:win10 + python2.7.14
#-*- encoding: utf-8 -*-
#author : beihuijie
#version 1.1
import re
import sys
import os
import countTime
def getParameters():
'''
get parameters from console command
'''
with open(sys.argv[1], "r") as fread:
lines = fread.readlines()
keywords=[]
for line in lines:
temp = line.split(', ')
keywords.append(temp)
for i in range(0, (len(keywords[0]) - 1)):
print ' Keyword = %s' % keywords[0][i]
return keywords[0]
def isFileExists(strfile):
'''
check the file whether exists
'''
return os.path.isfile(strfile)
def Search(keyword, filename):
'''
search the keyword in a assign file
'''
if(isFileExists(filename) == False):
print 'Input filepath is wrong,please check again!'
sys.exit()
linenum = 1
findtime = 0
with open(filename, 'r') as fread:
lines = fread.readlines()
for line in lines:
rs = re.findall(keyword, line, re.IGNORECASE)
if rs:
#output linenum of keyword place
sys.stdout.write('line:%d '%linenum)
lsstr = line.split(keyword)
strlength = len(lsstr)
findtime = findtime + 1
#print strlength
for i in range(strlength):
if(i < (strlength - 1)):
sys.stdout.write(lsstr[i].strip())
sys.stdout.write(keyword)
else:
sys.stdout.write(lsstr[i].strip() + '\n')
linenum = linenum + 1
print '+----------------------------------------------------------------------------+'
print (' Search result: find keyword: %s %d times'%(keyword, findtime))
print '+----------------------------------------------------------------------------+'
def executeSearch():
'''
this is a execute search method
'''
ls = getParameters()
start = countTime.getTime()
parameter_number = len(ls)
print 'Filename = %s ' % ls[parameter_number - 1]
print '--------------------start search-------------------------'
if(parameter_number >= 2):
for i in range(parameter_number - 1):
Search(ls[i], ls[parameter_number - 1])
else:
print 'There is a parameter error occured in executeSearch()!'
end = countTime.getTime()
print '+----------------------------------------------------------------------------+'
print ' Total cost time: %s'%countTime.formatTime(end - start)
print '+============================================================================+'
if __name__=='__main__':
executeSearch()
countTime.py
#-*- encoding: utf-8 -*- #author : beihuijie #version 1.1 import datetime import time def getTime(): ''' return time is format of time(unit is second) ''' return time.time() def getCPUClockTime(): ''' return time is CPU Clock time ''' return time.clock() def formatTime(timevalue): ''' format the time numbers ''' hour = 0 minute = 0 second = 0 if timevalue > 0: #count hour hour = timevalue // 3600 remain = timevalue % 3600 #count minute minute = remain // 60 remain = remain % 60 #count second second = round(remain, 3) return '%.0fh:%.0fm:%.3fs'%(hour, minute, second) if __name__=='__main__': value = 134.45632 print value print formatTime(value)
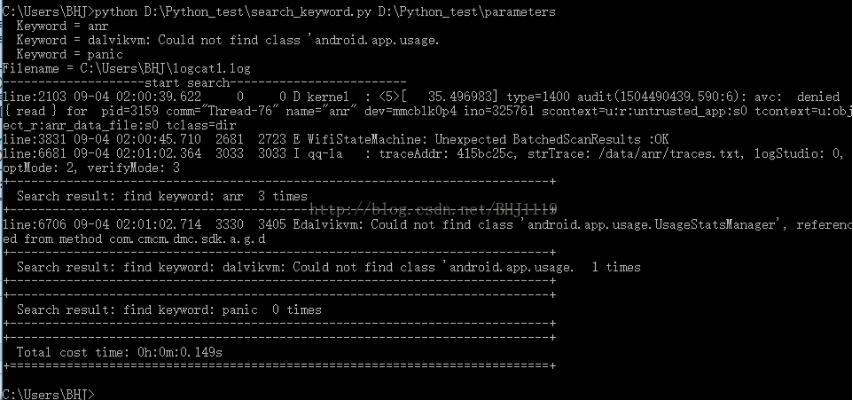
关键字及被扫描的日志路径信息,记录到文件中,以逗号+空格隔开,如,“, ”日志路径信息放到最后。
格式如下:
anr, dalvikvm: Could not find class 'android.app.usage., panic, C:\Users\BHJ\logcat1.log
执行结果:
以上这篇python实现扫描日志关键字的示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。