python实现自动登录
利用python,可以实现填充网页表单,从而自动登录WEB门户。
(注意:以下内容只针对python3)
环境准备:
(1)安装python
(2)安装splinter,下载源码 python setup install
#coding=utf-8
import time
from splinter import Browser
def login_mail(url):
browser = Browser()
#login 163 email websize
browser.visit(url)
#wait web element loading
#fill in account and password
browser.find_by_id('username').fill('你的用户名称')
browser.find_by_id('password').fill('你的密码')
#click the button of login
browser.find_by_id('loginBtn').click()
time.sleep(5)
#close the window of brower
browser.quit()
if __name__ == '__main__':
mail_addr ='http://reg.163.com/'
login_mail(mail_addr)
Tips:
(1)如果需要修改web的html属性,可以使用:js
browser.execute_script('document.getElementById("Html属性ID").value = "在此提供默认值"')
(2)browser = Browser()
不指定的情况下,浏览器驱动是火狐(Firefox),可以指定其他:browser = Browser(‘chrome'),需要下载对应的驱动程序
1.python3浏览页面
#coding=utf-8
import urllib.request
import time
#在请求加上头信息,伪装成浏览器访问
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
chaper_url='http://XXX'
vist_num=1
while vist_num<1000:
if vist_num%50==0:
time.sleep(5)
print("This is the 【 "+str(vist_num)+" 】次尝试")
req = urllib.request.Request(url=chaper_url, headers=headers)
urllib.request.urlopen(req).read() #.decode('utf-8')
vist_num+=1
2.python 多线程
#coding=utf-8
import threading #导入threading包
from time import sleep
import time
def fun1():
print ("Task 1 executed." )
time.sleep(3)
print ("Task 1 end." )
def fun2():
print ("Task 2 executed." )
time.sleep(5)
print ("Task 2 end." )
threads = []
t1 = threading.Thread(target=fun1)
threads.append(t1)
t2 = threading.Thread(target=fun2)
threads.append(t2)
for t in threads:
# t.setDaemon(True)
t.start()
3.利用python下载百度图片
#coding=utf-8
import urllib.request
import re
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?\.jpg)"'
imgre = re.compile(reg)
html=html.decode('utf-8')
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
print(str(x))
html = getHtml("http://image.baidu.com/channel?c=%E6%91%84%E5%BD%B1&t=%E5%85%A8%E9%83%A8&s=0")
print(getImg(html))
效果:
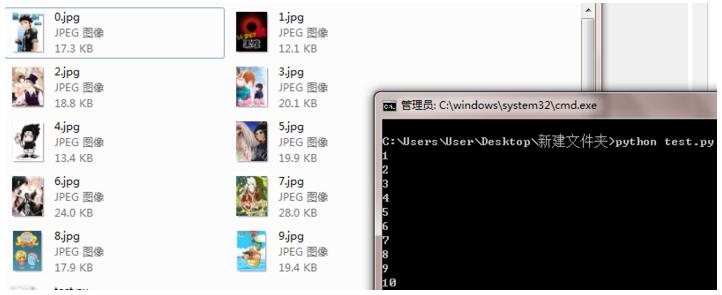
官网:链接地址
官方示例程序:链接地址
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。

