python re正则匹配网页中图片url地址的方法
最近写了个python抓取必应搜索首页http://cn.bing.com/的背景图片并将此图片更换为我的电脑桌面的程序,在正则匹配图片url时遇到了匹配失败问题。
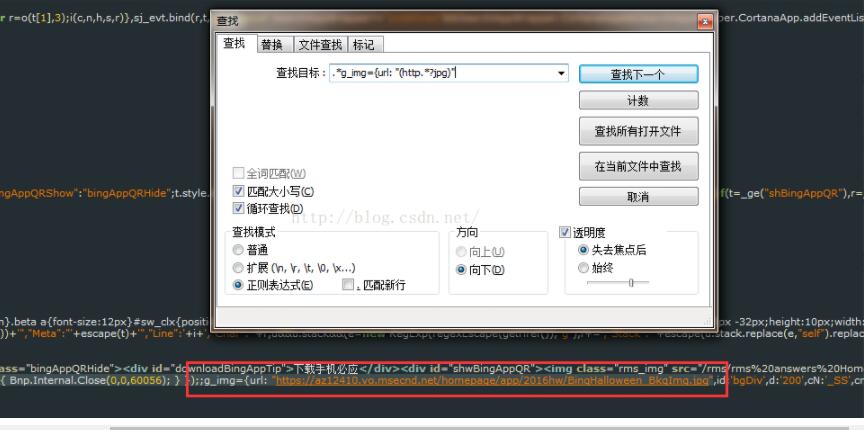
要抓取的图片地址如图所示:

首先,使用这个pattern
reg = re.compile('.*g_img={url: "(http.*?jpg)"')
无论怎么匹配都匹配不到,后来把网页源码抓下来放在notepad++中查看,并用notepad++的正则匹配查找,很轻易就匹配到了,如图:
后来我写了个测试代码,把图片地址在的那一行保存在一个字符串中,很快就匹配到了,如下面代码所示,data是匹配不到的,然而line是可以匹配到的。
# -*-coding:utf-8-*-
import os
import re
f = open('bing.html','r')
line = r'''Bnp.Internal.Close(0,0,60056); } });;g_img={url: "https://az12410.vo.msecnd.net/homepage/app/2016hw/BingHalloween_BkgImg.jpg",id:'bgDiv',d:'200',cN'''
data = f.read().decode('utf-8','ignore').encode('gbk','ignore')
print " "
reg = re.compile('.*g_img={url: "(http.*?jpg)"')
if re.match(reg, data):
m1 = reg.findall(data)
print m1[0]
else:
print("data Not match .")
print 20*'-'
#print line
if re.match(reg, line):
m2 = reg.findall(line)
print m2[0]
else:
print("line Not match .")
由此可见line和data是有区别的,什么区别呢?那就是data是多行的,包含换行符,而line是单行的,没有换行符。我有在字符串line中加了换行符,结果line没有匹配到。
到这了原因就清楚了。原因就在这句话
re.compile('.*g_img={url: "(http.*?jpg)"')。
后来翻阅python文档,发现re.compile()这个函数的第二个可选参数flags。这个参数是re中定义的常量,有如下常量
re.DEBUG Display debug information about compiled expression. re.I re.IGNORECASE Perform case-insensitive matching; expressions like [A-Z] will match lowercase letters, too. This is not affected by the current locale.
re.L re.LOCALE Make \w, \W, \b, \B, \s and \S dependent on the current locale.
re.M re.MULTILINE When specified, the pattern character '^' matches at the beginning of the string and at the beginning of each line (immediately following each newline); and the pattern character '$' matches at the end of the string and at the end of each line (immediately preceding each newline). By default, '^' matches only at the beginning of the string, and '$' only at the end of the string and immediately before the newline (if any) at the end of the string.
re.S re.DOTALL Make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline.re.U re.UNICODE Make \w, \W, \b, \B, \d, \D, \s and \S dependent on the Unicode character properties database.New in version 2.0.
re.X re.VERBOSE This flag allows you to write regular expressions that look nicer and are more readable by allowing you to visually separate logical sections of the pattern and add comments. Whitespace within the pattern is ignored, except when in a character class or when preceded by an unescaped backslash. When a line contains a # that is not in a character class and is not preceded by an unescaped backslash, all characters from the leftmost such # through the end of the line are ignored.
这里我们需要的就是re.S 让'.'匹配所有字符,包括换行符。修改正则表达式为
reg = re.compile('.*g_img={url: "(http.*?jpg)"', re.S)
即可完美解决问题。
以上这篇python re正则匹配网页中图片url地址的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。