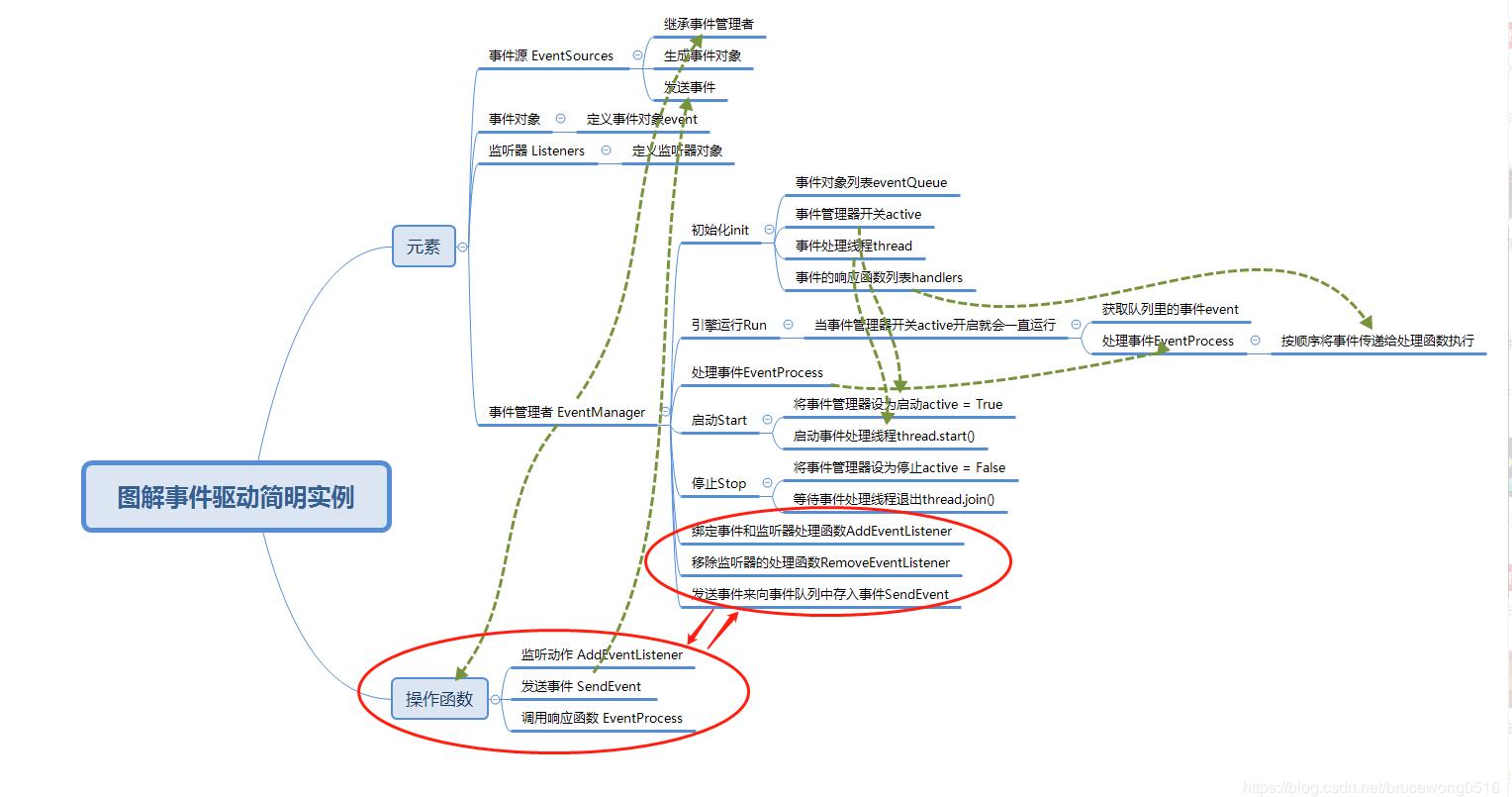
python使用suds调用webservice接口的方法
最近做接口对接,遇到了.net开发的webservice接口,因为python第一次与webservice对接,连问带查,最后使用suds库来实现了
1.安装suds
mac: sudo pip install suds
linux: easy_install suds
也可以通过去官网下载suds代码,再本地安装
2. 引用初始化
>>> from suds.client import Client >>> url = 'http://www.gpsso.com/webservice/kuaidi/kuaidi.asmx?wsdl' >>> client = Client(url) >>> print client Suds ( https://fedorahosted.org/suds/ ) version: 0.4 GA build: R699-20100913 Service ( Kuaidi ) tns="http://gpsso.com/" Prefixes (1) ns0 = "http://gpsso.com/" Ports (2): (KuaidiSoap) Methods (1): KuaidiQuery(xs:string Compay, xs:string OrderNo, ) Types (1): ApiSoapHeader (KuaidiSoap12) Methods (1): KuaidiQuery(xs:string Compay, xs:string OrderNo, ) Types (1): ApiSoapHeader >>>
对url做一下说明,一般要确认给的wsdl地址是正常模式,地址打开一般为xml格式而有些服务是做成了html模式,这个会导致实例化或者调用方法的时候出现xml解析异常。
3. 方法调用
2中的client打印出来就可以知道,该webserviece服务定义了什么方法,方法需要什么参数,声明了什么信息等(如头信息,ApiSoapHeader),方法可以通过client.serviece直接调用
>>> client.service.KuaidiQuery(Company='EMS', OrderNo='1111')
(KuaidiQueryResult){
API =
(API){
RESULTS = "0"
MESSAGE = "接口查询成功"
}
}
>>>
而声明的头信息,则可以用factory的方式去实例化
>>> header = client.factory.create('ApiSoapHeader')
>>> print header
(ApiSoapHeader){
APICode = None
APIKey = None
}
>>> header.APICode = '123'
>>> header.APIKey = 'key123'
>>> print header
(ApiSoapHeader){
APICode = "123"
APIKey = "key123"
}
>>>
头信息需要用set_options方法设置
>>> >>> client.set_options(soapheaders=[header,]) >>>
如果没有描述的头信息,可以通过查阅文档https://fedorahosted.org/suds/wiki/Documentation查询custom soap headers来设置
以上这篇python使用suds调用webservice接口的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。