Python数据预处理之数据规范化(归一化)示例
本文实例讲述了Python数据预处理之数据规范化。分享给大家供大家参考,具体如下:
数据规范化
为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化(归一化)处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析。
数据规范化方法主要有:
- 最小-最大规范化
- 零-均值规范化
数据示例
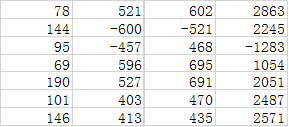
代码实现
#-*- coding: utf-8 -*- #数据规范化 import pandas as pd import numpy as np datafile = 'normalization_data.xls' #参数初始化 data = pd.read_excel(datafile, header = None) #读取数据 (data - data.min())/(data.max() - data.min()) #最小-最大规范化 (data - data.mean())/data.std() #零-均值规范化
从命令行可以看到下面的输出:
>>> (data-data.min())/(data.max()-data.min(
0 1 2 3
0 0.074380 0.937291 0.923520 1.000000
1 0.619835 0.000000 0.000000 0.850941
2 0.214876 0.119565 0.813322 0.000000
3 0.000000 1.000000 1.000000 0.563676
4 1.000000 0.942308 0.996711 0.804149
5 0.264463 0.838629 0.814967 0.909310
6 0.636364 0.846990 0.786184 0.929571>>> (data-data.mean())/data.std()
0 1 2 3
0 -0.905383 0.635863 0.464531 0.798149
1 0.604678 -1.587675 -2.193167 0.369390
2 -0.516428 -1.304030 0.147406 -2.078279
3 -1.111301 0.784628 0.684625 -0.456906
4 1.657146 0.647765 0.675159 0.234796
5 -0.379150 0.401807 0.152139 0.537286
6 0.650438 0.421642 0.069308 0.595564
上述代码改为使用print语句打印,如下:
#-*- coding: utf-8 -*- #数据规范化 import pandas as pd import numpy as np datafile = 'normalization_data.xls' #参数初始化 data = pd.read_excel(datafile, header = None) #读取数据 print((data - data.min())/(data.max() - data.min())) #最小-最大规范化 print((data - data.mean())/data.std()) #零-均值规范化
可输出如下打印结果:
0 1 2 3
0 0.074380 0.937291 0.923520 1.000000
1 0.619835 0.000000 0.000000 0.850941
2 0.214876 0.119565 0.813322 0.000000
3 0.000000 1.000000 1.000000 0.563676
4 1.000000 0.942308 0.996711 0.804149
5 0.264463 0.838629 0.814967 0.909310
6 0.636364 0.846990 0.786184 0.929571
0 1 2 3
0 -0.905383 0.635863 0.464531 0.798149
1 0.604678 -1.587675 -2.193167 0.369390
2 -0.516428 -1.304030 0.147406 -2.078279
3 -1.111301 0.784628 0.684625 -0.456906
4 1.657146 0.647765 0.675159 0.234796
5 -0.379150 0.401807 0.152139 0.537286
6 0.650438 0.421642 0.069308 0.595564
附:代码中使用到的normalization_data.xls点击此处本站下载。
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
