python使用selenium登录QQ邮箱(附带滑动解锁)
前言
最近因为工作需要 用selenium做了一个QQ邮箱的爬虫(登录时部分帐号要滑动解锁),先简单记录一下。
这个问题先可以分为两个部分:1.登录帐号和2.滑动解锁。python版本3.5.4
问题分析:登录+滑动解锁
其实登录账号的部分本来很简单,用selenium打开QQ邮箱官网:https://mail.qq.com 然后切换frame输入帐号
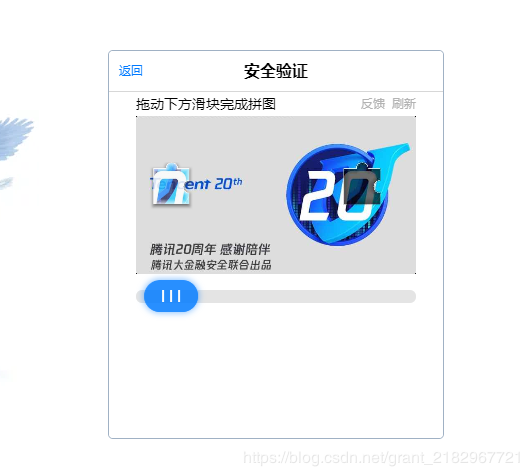
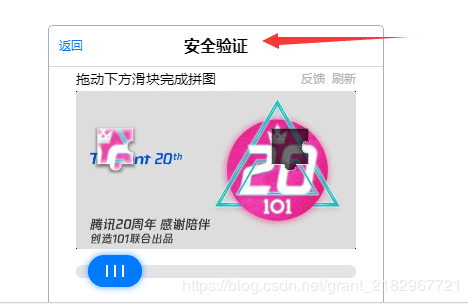
和密码点击登录即可,但是部分账号,或者可以说是异地登录的QQ账号需要滑动解锁验证码才能继续登录(下图)
看到这张图我们应该不难想到:
1、我们需要模拟人拖动按钮
2、按钮拖动的距离=拼图间的距离
这个明确了之后那接下来我们先看看拼图间的距离到底怎么算。登录虽然不难,但还是写一下,免得说我偷懒0.0
1.1 登录
# coding = utf-8
from selenium import webdriver
import time
import random
from utils import DbUtil
import uuid
from selenium.webdriver import ActionChains
from PIL import Image as Im
import os
import cv2
import numpy as np
import requests
from pymongo import MongoClient
# 代码1.1 目前只用到webdriver和time库 其他的会在下面用到
# u 帐号,p 密码
def Email(u, p):
# 定义QQ邮箱的登录页
start_url = "https://mail.qq.com"
# 这里我用的是火狐浏览器。很多人喜欢定义成driver 我喜欢定义成browser
browser = webdriver.Firefox()
# 休息2s
time.sleep(2)
# 使用火狐浏览器打开QQ邮箱的登录页
browser.get(start_url)
# 休息2s(这个sleep时间因网速而异,部分的错误就是因为网站还没打开你就开始获取网页的标签进行操作,当然就获取不到然后报错了~)
time.sleep(2)
# 切换frame。login_frame是该登录窗口iframe的id
browser.switch_to.frame("login_frame")
# 点击选择帐号密码登录
browser.find_element_by_id("switcher_plogin").click()
# 休息1s
time.sleep(1)
# 输入帐号 将u填入id是u的输入框
browser.find_element_by_id("u").send_keys(u)
time.sleep(1)
# 输入密码 将p填入id是p的输入框
browser.find_element_by_id("p").send_keys(p)
time.sleep(1)
# 点击登录 登录按钮的id是login_button
browser.find_element_by_id("login_button").click()
# main方法
if __name__ == '__main__':
# 为了实现异地登录 随意定义一个QQ号(反正我们的目的是滑动解锁0.0),如果直接提示帐号密码错误没有验证码的话就再随意编一个QQ号
Email(u="123456789", p="abcdefg")
运行一下 应该就能看到我们要的滑动验证码了
1.2 获取验证码图片
我们在运行完上面的代码之后验证码应该出来了,首先我们需要将其中的拼图和完整图片下载下来用于后面的距离计算。
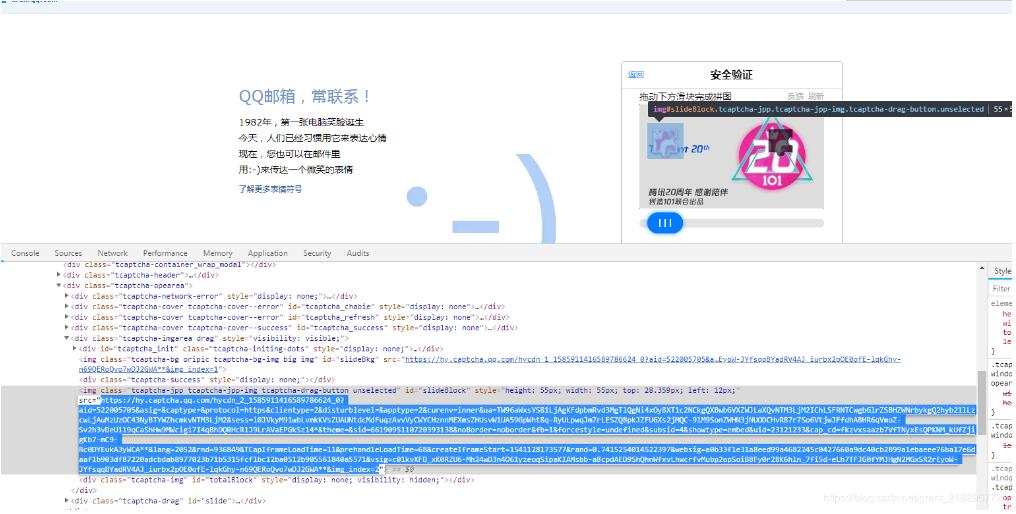
我们先F12 然后
点击左侧的小拼图查看元素↓
点击大拼图查看元素↓
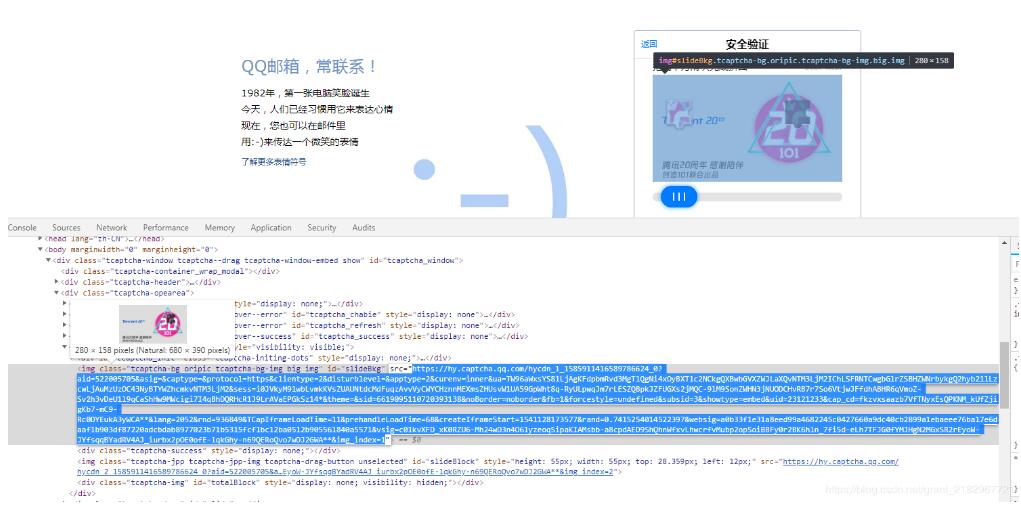
以上选中的这两张图片就是我们后面要用来计算滑动距离的图片
要获取到图片需要两步:
1、获取到图片的链接(上面已经能看到了)
2、根据链接将图片下载到本地处理
回到刚才的代码 我们需要先加个判断来识别是否出现了滑动验证码(有的时候会直接提示帐号密码错误)
只要判断这个"安全验证"的提示就可以说明是有滑动验证码的,反之没有。
# 代码1.1省略....↑
# 代码1.2.1
# 判断是否出现了滑动验证码
try:
# 先切换frame回到默认
browser.switch_to.default_content()
# 将frame切换到 login_frame(也就是之前的登录frame)
browser.switch_to.frame("login_frame")
# 根据xpath获取到含有安全提示的标签然后将其中文本获取到打印出来 如果异常就进except块 说明没有验证码
code = browser.find_element_by_xpath('//*[@id="newVcodeArea"]/div[1]/div/div[2]').text
print(code)
except :
print('无安全验证码!')
这块代码写完我们基本上实现了登录和判断是否出现滑动验证码的功能,不多BB我们继续↓
出现滑动验证码的时候我们先点击刷新

此处要加入两个方法用来解决: 下载图片的问题和计算拼图还原的问题
我们先下载图片到本地 然后通过处理图片来计算拼图还原的距离
# 代码2
# 图片下载到本地,返回一个本地链接。url 是图片的链接,type区分左侧小拼图和大图,大图传big,小图传small
def pic_download(url,type):
url = url
root = "D:/emils_python/pic_test/"
# path = root + str(time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()))+'.png'
path = root + type + '.png'
try:
if not os.path.exists(root):
os.mkdir(root)
if os.path.exists(path):
os.remove(path)
r = requests.get(url)
r.raise_for_status()
# 使用with语句可以不用自己手动关闭已经打开的文件流
with open(path, "wb") as f: # 开始写文件,wb代表写二进制文件
f.write(r.content)
print(f.name)
print("下载完成")
return f.name
except Exception as e:
print("获取失败!" + str(e))
到这里图片下载的方法就ok了↑ 然后继续写计算拼图还原的方法↓
# 代码3
# 获取缺口位置 small_url是小图的路径(本地),big_url是大图的路径(本地) 最后return一个计算出的距离
def get_distance(small_url,big_url):
# 引用上面的图片下载
otemp = pic_download(small_url,'small')
time.sleep(2)
# 引用上面的图片下载
oblk = pic_download(big_url,'big')
# 计算拼图还原距离
target = cv2.imread(otemp, 0)
template = cv2.imread(oblk, 0)
w, h = target.shape[::-1]
temp = 'temp.jpg'
targ = 'targ.jpg'
cv2.imwrite(temp, template)
cv2.imwrite(targ, target)
target = cv2.imread(targ)
target = cv2.cvtColor(target, cv2.COLOR_BGR2GRAY)
target = abs(255 - target)
cv2.imwrite(targ, target)
target = cv2.imread(targ)
template = cv2.imread(temp)
result = cv2.matchTemplate(target, template, cv2.TM_CCOEFF_NORMED)
x, y = np.unravel_index(result.argmax(), result.shape)
# 缺口位置
print((y, x, y + w, x + h))
# 调用PIL Image 做测试
image = Im.open(oblk)
xy = (y + 20, x + 20, y + w - 20, x + h - 20)
# 切割
imagecrop = image.crop(xy)
# 保存切割的缺口
imagecrop.save("D:/emils_python/pic_test/new_image.jpg")
return y
到这里计算拼图还原的距离的方法基本上就完成了↑
有了下载图片和计算拼图还原的方法 我们就可以直接调用get_distance方法计算拼图还原的距离
# 代码1.1省略....↑
# 还是代码1.2
# 判断是否出现了滑动验证码
try:
# 先切换frame回到默认
browser.switch_to.default_content()
# 将frame切换到 login_frame(也就是之前的登录frame)
browser.switch_to.frame("login_frame")
# 根据xpath获取到含有安全提示的标签然后将其中文本获取到打印出来 如果异常就进except块 说明没有验证码
code = browser.find_element_by_xpath('//*[@id="newVcodeArea"]/div[1]/div/div[2]').text
print(code)
# 如果后面拖动失败 我们就再次循环 所以用while
while True:
# 切换frame
browser.switch_to.default_content()
# 切换frame
browser.switch_to.frame('login_frame')
# 切换带有刷新按钮的frame
browser.switch_to.frame(browser.find_element_by_xpath('//*[@id="newVcodeIframe"]/iframe'))
# 点击刷新 id为e_reload
browser.find_element_by_id('e_reload').click()
# 获取图片链接
big_url = browser.find_element_by_id('slideBkg').get_attribute('src')
small_url = browser.find_element_by_id('slideBlock').get_attribute('src')
# 下载图片并计算拼图还原的距离
y = get_distance(small_url, big_url)
# 获取当前网页链接,用于判断拖动验证码后是否成功,如果拖动后地址没变则为失败
url1 = browser.current_url
# 获取蓝色拖动按钮对象
element = browser.find_element_by_id('tcaptcha_drag_button')
# 计算distance
distance = y * (280 / 680) - 21
print('distance:', distance)
except :
print('无安全验证码!')
写到这里 基本上我们可以计算出拼图还原的距离了。
是不是开始看着觉得很有道理…突然看到最后两行…WTF??? distance = y * (280 / 680) - 21 是什么意思?
别着急慢慢解释…通过上面的代码已经知道了 y 就是图片还原的距离,但是我们还少考虑了2点:
1.图片的起始位置其实不是最左侧,而是向右偏移了一点
2.我们从下载到本地的图片尺寸是否跟网页上的图片尺寸一致 ? 答案当然是否定的。
我们先看一下拼图起始的位置

很清晰的能看到拼图到左边的有一段距离 那到底是多少呢 ? 我已经找人用专业的工具测过了:21左右
为了好理解 我特地用手机拍了张照片又截图下来,自己体会一下… 就是个大概的意思 为了好理解…

以上是拼图到左侧的距离 然后我们再看一下我们在本地处理并计算的图片尺寸和网页上的图片有什么区别
先看本地处理过后的图片

很明显能够看到长是680
我们再看一下网页上的…没错还是我找的人用专业工具给测的…280,笨笨的老方法帮你们理解一下

所以我们讲了这么多 会发现 :
按钮需要滑动的距离(网页) = 拼图的还原距离(本地图片) * (网页上的长度 / 本地图片的长度) -21(多出来的起始位置)
也就是前面会让人疑惑的 distance = y * (280 / 680) - 21 当然 这些都因实际情况而定
到了这一步 可以说我们最难的部分已经解决了
有了滑动距离 我们就只剩拖动按钮这一步了,先看代码
# 省略上面的代码 1.1 和1.2 # 代码1.3 # 接着上面的 distance = y * (280 / 680) - 21 继续 # 模拟人为拖动按钮 has_gone_dist = 0 remaining_dist = distance # distance += randint(-10, 10) # 按下鼠标左键 ActionChains(browser).click_and_hold(element).perform() time.sleep(0.5) while remaining_dist > 0: ratio = remaining_dist / distance if ratio < 0.2: # 开始阶段移动较慢 span = random.randint(5, 8) elif ratio > 0.8: # 结束阶段移动较慢 span = random.randint(5, 8) else: # 中间部分移动快 span = random.randint(10, 16) ActionChains(browser).move_by_offset(span, random.randint(-5, 5)).perform() remaining_dist -= span has_gone_dist += span time.sleep(random.randint(5, 20) / 100) ActionChains(browser).move_by_offset(remaining_dist, random.randint(-5, 5)).perform() ActionChains(browser).release(on_element=element).perform()
到这里按钮拖动就已经完成了,但图片分析不是人在操作毕竟有误差,所以我们需要判断滑动按钮是否已经成功,如果失败了我们得让程序继续循环去刷新验证码然后拖动直到成功为止
# 省略代码 1.1, 1.2, 1.3 在1.3下继续写
# 获取当前的网页地址
url2 = browser.current_url
# frame切回到上一层
browser.switch_to.parent_frame()
# 判断拖动按钮后网页地址是否有改变,如果变了则说明登录成功(失败则停留在该页面)
if url1 == url2:
try :
print(browser.find_element_by_class_name('tcaptcha-title').text)
print('滑动失败!')
except :
print('帐号密码有误!')
else :
print('登录成功!')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。