pandas计数 value_counts()的使用
在pandas里面常用value_counts确认数据出现的频率。
1. Series 情况下:
pandas 的 value_counts() 函数可以对Series里面的每个值进行计数并且排序。
import pandas as pd
df = pd.DataFrame({'区域' : ['西安', '太原', '西安', '太原', '郑州', '太原'],
'10月份销售' : ['0.477468', '0.195046', '0.015964', '0.259654', '0.856412', '0.259644'],
'9月份销售' : ['0.347705', '0.151220', '0.895599', '0236547', '0.569841', '0.254784']})
print(df)
统计每个区域出现多少次:
print(df['区域'].value_counts())

每个区域都被计数,并且默认从高到低排序。
如果想升序排列,设置参数 ascending = True:
print(df['区域'].value_counts(ascending=True))

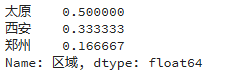
如果想得出计数占比,可以加参数 normalize=True
print(df['区域'].value_counts(normalize=True))
注:空值默认剔除掉的。value_counts()返回的结果是一个Series数组,可以跟别的数组进行计算。
2. DataFrame 情况下:
import pandas as pd
df = pd.DataFrame({'区域1' : ['西安', '太原', '西安', '太原', '郑州', '太原'],
'区域2' : ['太原', '太原', '西安', '西安', '西安', '太原']})
print(df.apply(pd.value_counts))

区域2中没有郑州,所以是NaN。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。