Pycharm运行加载文本出现错误的解决方法
Pycharm打开大文件的时候出现这个错误,根据提示以及百度知道,是因为IDEA对能关联的文件大小做了限制,主要是为了保护内存,默认值为2500kb。然后根据百度上的教程修改
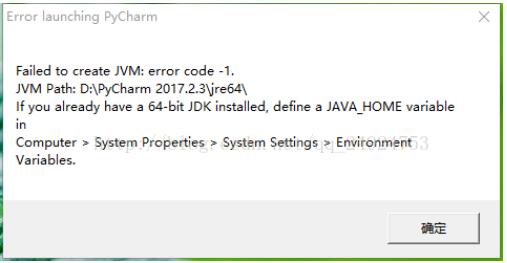
修改bin文件中的idea.properties并没有改变情况,修改pycharm64.exe.vmoptions文件,重启pycharm就出现如图所示的错误
最后修改pycharm.exe.vmoptions 这个配置文件,修改里面的配置
-Xms1024m
-Xmx2048m
-XX:MaxPermSize=1024m
-XX:ReservedCodeCacheSize=1024m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=50
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
这里说明一下:
-Xms JVM初始分配的堆内存
-Xmx JVM最大允许分配的堆内存,按需分配
-XX:PermSize JVM初始分配的非堆内存
-XX:MaxPermSize JVM最大允许分配的非堆内存,按需分配
这几个参数的大小有限制 xms不能大于xmx maxpermsize 一般不大于xmx 如果设置错就会出现如图所示的这种情况.
这个问题仍然没有解决,但是我发现在pycharm的bin文件夹下有一个Pycharm.exe可以直接运行,但是运行pycharm64.exe就不可以 。然后重启运行pycharm.exe大文件加载的问题也解决了。
如果有知道原因的朋友,希望能告诉我原因啦,谢谢~
以上这篇Pycharm运行加载文本出现错误的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。