基于sklearn实现Bagging算法(python)
本文使用的数据类型是数值型,每一个样本6个特征表示,所用的数据如图所示:
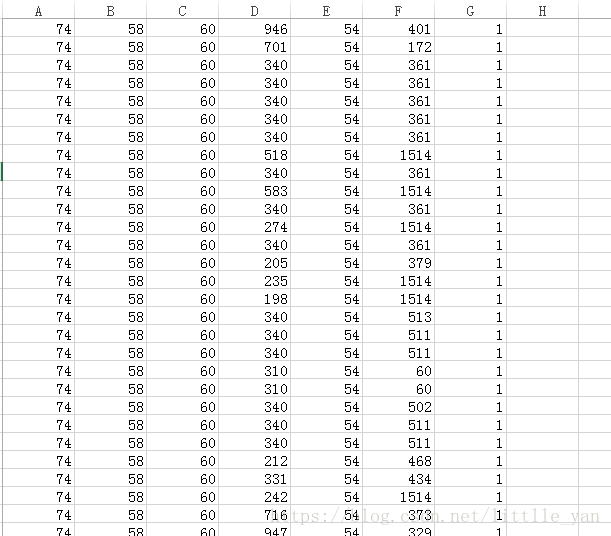
图中A,B,C,D,E,F列表示六个特征,G表示样本标签。每一行数据即为一个样本的六个特征和标签。
实现Bagging算法的代码如下:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
import csv
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
data=[]
traffic_feature=[]
traffic_target=[]
csv_file = csv.reader(open('packSize_all.csv'))
for content in csv_file:
content=list(map(float,content))
if len(content)!=0:
data.append(content)
traffic_feature.append(content[0:6])//存放数据集的特征
traffic_target.append(content[-1])//存放数据集的标签
print('data=',data)
print('traffic_feature=',traffic_feature)
print('traffic_target=',traffic_target)
scaler = StandardScaler() # 标准化转换
scaler.fit(traffic_feature) # 训练标准化对象
traffic_feature= scaler.transform(traffic_feature) # 转换数据集
feature_train, feature_test, target_train, target_test = train_test_split(traffic_feature, traffic_target, test_size=0.3,random_state=0)
tree=DecisionTreeClassifier(criterion='entropy', max_depth=None)
# n_estimators=500:生成500个决策树
clf = BaggingClassifier(base_estimator=tree, n_estimators=500, max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=1, random_state=1)
clf.fit(feature_train,target_train)
predict_results=clf.predict(feature_test)
print(accuracy_score(predict_results, target_test))
conf_mat = confusion_matrix(target_test, predict_results)
print(conf_mat)
print(classification_report(target_test, predict_results))
运行结果如图所示:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。