Tensorflow实现酸奶销量预测分析
本文实例为大家分享了Tensorflow酸奶销量预测分析的具体代码,供大家参考,具体内容如下
# coding:utf-8
# 酸奶成本为1元,利润为9元
# 预测少了相应的损失较大,故不要预测少
# 导入相应的模块
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
BATCH_SIZE=8
SEED=23455
COST=3
PROFIT=4
rdm=np.random.RandomState(SEED)
X=rdm.randn(100,2)
Y_=[[x1+x2+(rdm.rand()/10.0-0.05)] for (x1,x2) in X]
# 定义神经网络的输入、参数和输出,定义向前传播过程
x=tf.placeholder(tf.float32,shape=(None,2))
y_=tf.placeholder(tf.float32,shape=(None,1))
w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1))
y=tf.matmul(x,w1)
# 定义损失函数和反向传播过程
loss=tf.reduce_sum(tf.where(tf.greater(y,y_),(y-y_)*COST,(y_-y)*PROFIT)) #损失函数要根据不同的模型进行变换
train_step=tf.train.GradientDescentOptimizer(0.001).minimize(loss)
# sess=tf.Session()
# STEPS=20000
# init_op=tf.global_variables_initializer()
# sess.run(init_op)
# for i in range(STEPS):
# start=(i*BATCH_SIZE)%32
# end=start+BATCH_SIZE
# sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
# if i%500==0:
#
# print("After %d steps,w1 is %f",(i,sess.run(w1)))
sess=tf.Session()
init_op=tf.global_variables_initializer()
sess.run(init_op)
STEPS=20000
for i in range(STEPS):
start=(i*BATCH_SIZE)%100
end=start+BATCH_SIZE
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%500==0:
print("After %d steps"%(i))
# print(sess.run(loss_mse))
# print("Loss is:%f",sess.run(loss_mse,feed_dict={y_:Y_,y:Y_}))
print("w1 is:",sess.run(w1))
print("Final is :",sess.run(w1))
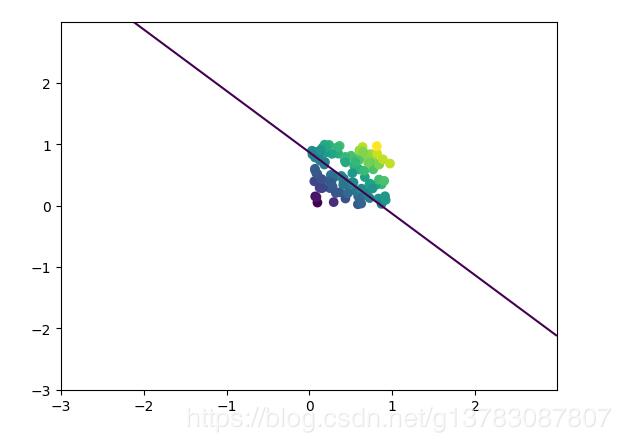
xx,yy=np.mgrid[-3:3:.01,-3:3:.01]
grid=np.c_[xx.ravel(),yy.ravel()]
probs=sess.run(y,feed_dict={x:grid})
probs=probs.reshape(xx.shape)
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_))
plt.contour(xx,yy,probs,[.9])
plt.show()
通过改变COST和PROFIT的值近而可以得出,当COST=1,PROFIT=9时,基于损失函数,模型的w1=1.02,w2=1.03说明模型会往多了预测;当COST=9,PROFIT=1时模型的w1=0.96,w2=0.97说明模型在往少了预测。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。