python实现几种归一化方法(Normalization Method)
数据归一化问题是数据挖掘中特征向量表达时的重要问题,当不同的特征成列在一起的时候,由于特征本身表达方式的原因而导致在绝对数值上的小数据被大数据“吃掉”的情况,这个时候我们需要做的就是对抽取出来的features vector进行归一化处理,以保证每个特征被分类器平等对待。下面我描述几种常见的Normalization Method,并提供相应的python实现(其实很简单):
1、(0,1)标准化:
这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理:
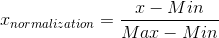
LaTex:{x}_{normalization}=\frac{x-Min}{Max-Min}
Python实现:
def MaxMinNormalization(x,Max,Min): x = (x - Min) / (Max - Min); return x;
找大小的方法直接用np.max()和np.min()就行了,尽量不要用python内建的max()和min(),除非你喜欢用List管理数字。
2、Z-score标准化:
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布,个人认为在一定程度上改变了特征的分布,关于使用经验上欢迎讨论,我对这种标准化不是非常地熟悉,转化函数为:

LaTex:{x}_{normalization}=\frac{x-\mu }{\sigma }
Python实现:
def Z_ScoreNormalization(x,mu,sigma): x = (x - mu) / sigma; return x;
这里一样,mu(即均值)用np.average(),sigma(即标准差)用np.std()即可。
3、Sigmoid函数
Sigmoid函数是一个具有S形曲线的函数,是良好的阈值函数,在(0, 0.5)处中心对称,在(0, 0.5)附近有比较大的斜率,而当数据趋向于正无穷和负无穷的时候,映射出来的值就会无限趋向于1和0,是个人非常喜欢的“归一化方法”,之所以打引号是因为我觉得Sigmoid函数在阈值分割上也有很不错的表现,根据公式的改变,就可以改变分割阈值,这里作为归一化方法,我们只考虑(0, 0.5)作为分割阈值的点的情况:


LaTex:{x}_{normalization}=\frac{1}{1+{e}^{-x}}
Python实现:
def sigmoid(X,useStatus): if useStatus: return 1.0 / (1 + np.exp(-float(X))); else: return float(X);
这里useStatus管理是否使用sigmoid的状态,方便调试使用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。

