Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程:
使用Python3.6.4环境(对中文支持比较好),安装Pandas包
pip install pandas
基本使用:
import pandas as pd
import numpy as np #进行具体的sum,count等计算时候要用到的
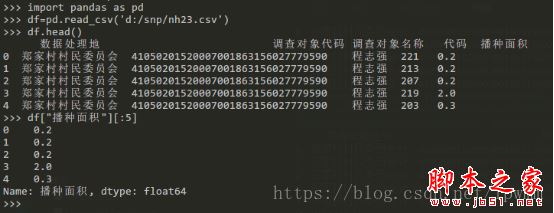
df=pd.read_csv('d:/snp/nh23.csv') #这里绝对路径一定要用/,windows下也是如此,不加参数默认csv文件首行为标题行
df.head() #查看引入的csv文件前5行数据
df[“播种面积”] #查看指定列,后面跟[:5]查看前5行数据
df[“调查对象代码”].str[:6] #获取指定列前6位字符串
df["ADDR"]=df["调查对象代码"].str[:6] #将上一行处理后的6位地址码作为新列ADDR插入

gp=df.groupby(["ADDR","代码"])["播种面积"].sum() #根据ADDR和代码进行分组后对播种面积列进行sum求和计算
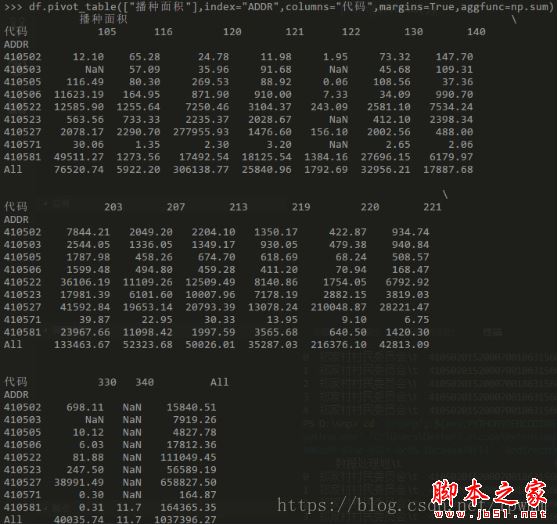
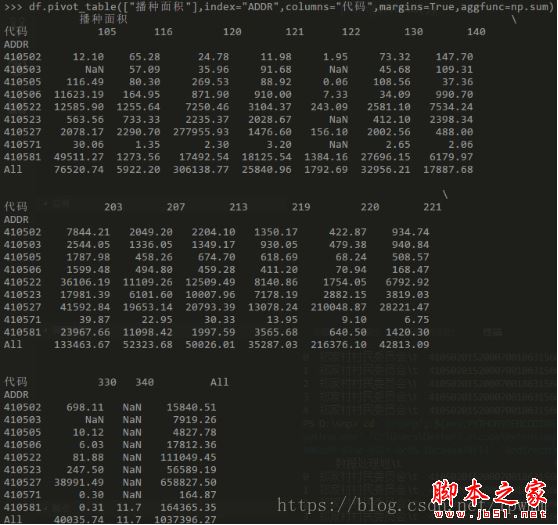
pv=df.pivot_table(["播种面积"],index="ADDR",columns="代码",margins=True,aggfunc=np.sum,fill_value=0) #数据透视图,对播种面积列进行汇总计算,index为行,columns为列,margins=True增加一个全部行汇总,aggfunc=np.sum透视图中对播种面积值进行sum计算,这里np是开头import的numpy as np,fill_value=0对空值进行0替换,否则没有数据会显示NaN
pv.to_csv("d:/snp/test.csv") #写入csv文件
总结
以上所述是小编给大家介绍的Python使用Pandas对csv文件进行数据处理的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!