pandas 选取行和列数据的方法详解
前言
本文介绍在 pandas 中如何读取数据行列的方法。数据由行和列组成,在数据库中,一般行被称作记录 (record),列被称作字段 (field)。回顾一下我们对记录和字段的获取方式:一般情况下,字段根据名称获取,记录根据筛选条件获取。比如获取 student_id 和 studnent_name 两个字段;记录筛选,比如 sales_amount 大于 10000 的所有记录。对于熟悉 SQL 语句的人来说,就是下面的语句:
select student_id, student_name from exam_scores where chinese >= 90 and math >= 90
上面的 SQL 语句表示从考试成绩表 (exam_scores) 中,筛选出语文和数学都大于或等于 90 分的所有学生 id 和 name。学习 pandas 数据获取,推荐这种以数据处理的目标为导向的方式,而不是被动的按 pandas 提供的 loc, iloc的语法中,一条条顺序学习。
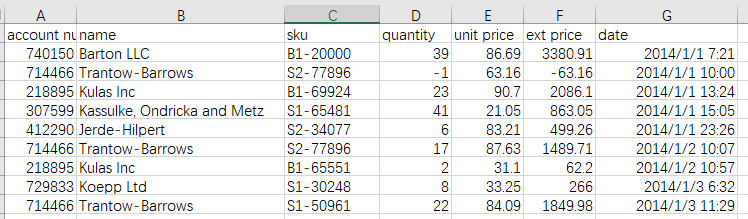
本篇我们要分析的关于销售数量和金额的一组数据,数据存放在 csv 文件中。示例数据我在 github 上放了一份,方便大家对照练习。
选择列
以下两种方法返回 Series 类型:
import pandas as pd
df = pd.read_csv('sample-salesv3.csv')
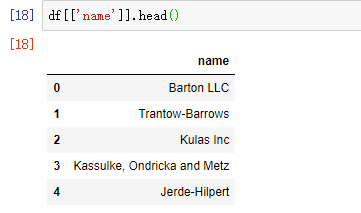
df.name
# 或者
df['name']
如果需要返回 DataFrame 格式,使用 list 作为参数。为了方便说明,给出在 jupyter notebook 中显示的界面。
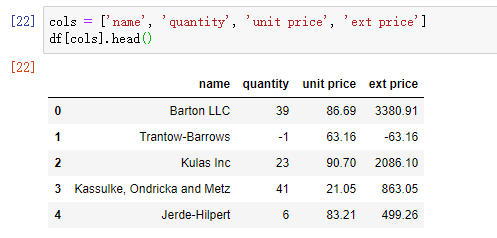
如果需要选取多列,传给 DataFrame 一个包含列名的 list:
选择行
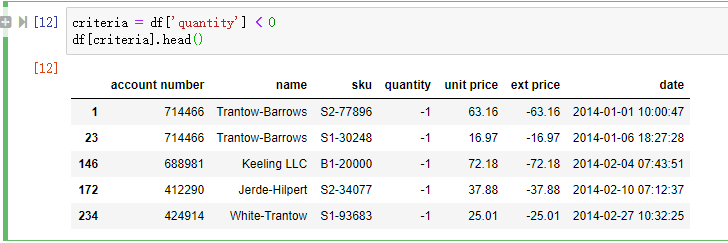
假设我们要筛选 quantity < 0 的所有记录:
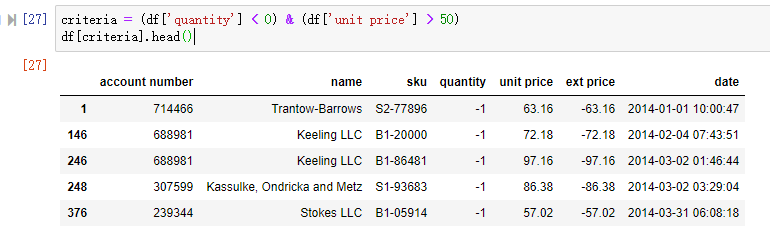
按多条件筛选的处理方式。假设想筛选 quantity < 0 并且 unit price > 50 的所有记录:
代码:
criteria = (df['quantity'] < 0) & (df['unit price'] > 50) df[criteria].head()
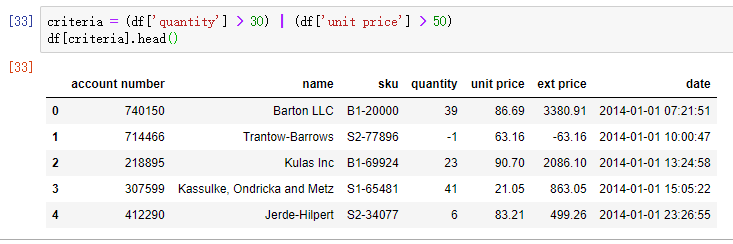
在 pandas 中,AND 条件的运算符为 & ,OR 条件的运算符为 |。假设想筛选所有 quantity > 30 或 unit price > 50 的记录:
代码:
criteria = (df['quantity'] > 30) | (df['unit price'] > 50) df[criteria].head()
基于字符串的记录筛选
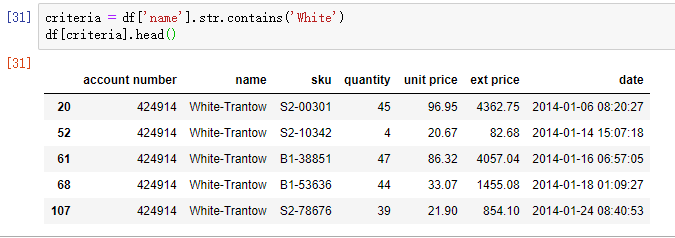
如果筛选条件为基于字符串,可以使用用 Series.str.xxx 方法,主要有 startswith, endswith 和 contains等。举一个例子,筛选出所有 name 含有 White 的记录:
代码:
criteria = df['name'].str.contains('White')
df[criteria].head()
这里解释一下 pandas 布尔索引 (boolean indexing) 的概念。布尔索引的意思是首先构建一个与 DataFrame 的 index 长度相同的一个 boolean 向量 (boolean vector),这个向量中只包含 True 或者 False,布尔索引是一个 Series。
然后 DataFrame 在筛选的时候,基于 DataFrame 的行索引,当布尔索引相同行索引所在行的 value 为 True 时,DataFrame 的这一行就包含在筛选之中,否则就排除在外。
为了能看得更加清晰,我们把上面的例子用另外一个方法来展示。创建一个新列:is_selected,这一列是一个布尔索引。
df['is_selected'] = df['name'].str.contains('White')
我们看到,is_selected 由 True 和 False 构成。
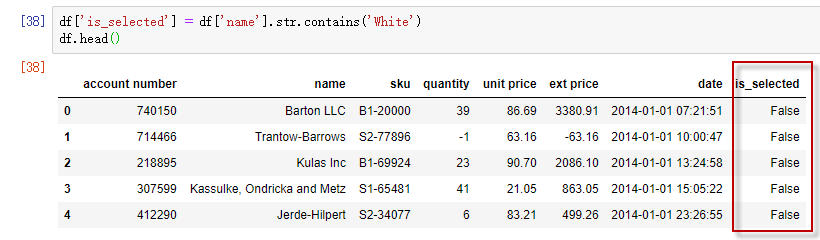
构建了 is_selected 列之后,通过df[df['name'].str.contains('White')] 筛选与下面的语句作用相同:
df[df['is_selected'] == True]
可以把 df['name'].str.contains('White') 这个布尔索引理解为构建了一个新列,然后基于这一列进行筛选。
基于 DateTime 类型的记录筛选
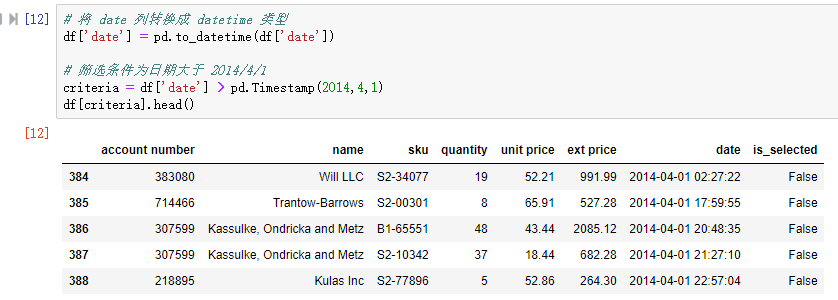
如果列的类型是 DateTime 类型,比如本示例的 date 列。pandas 读取 csv 文件时,date 列是 str 类型,所以我们先将 date 列转换成 datetime 类型,然后基于 pandas 的 Timestamp 类型构建筛选条件。
# 将 date 列转换成 datetime 类型 df['date'] = pd.to_datetime(df['date']) # 筛选条件为日期大于 2014/4/1 criteria = df['date'] > pd.Timestamp(2014,4,1) df[criteria].head()
同时选择行和列
如果基于本篇所说的模式,同时选择行和列,最简单的方法是组合,比如先基于行构建 DataFrame,然后再基于这个 DataFrame 选取需要的列:
where = df['name'].str.contains('White')
cols = ['name', 'quantity', 'unit price', 'ext price']
df[where][cols].head()

参考
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。