python如何从文件读取数据及解析
读取整个文件:
首先创建一个文件,例如我创建了一个t x t文件了。
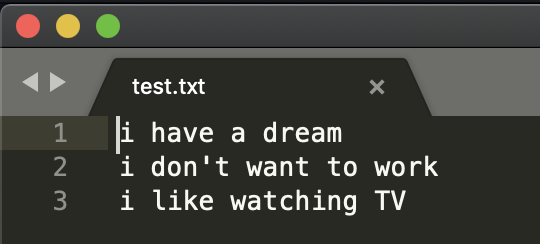
然后我想读取这个文件了,我首先将上面的这个文件保存在我即将要创建的Python的文件目录下,
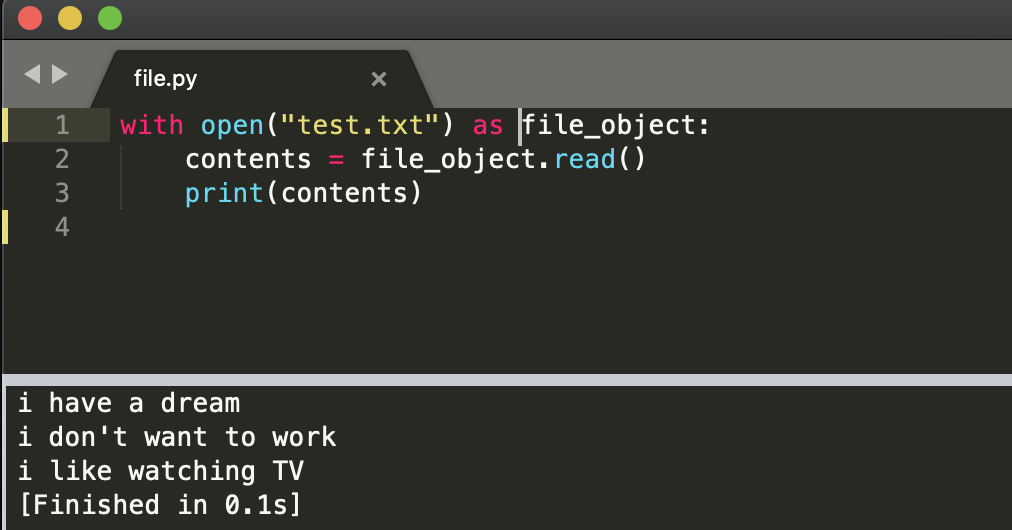
即读取文件成功。
解析:
函数open()接受一个参数:即要打开的文件的名称。python在当前执行的文件所在的目录中查找指定文件。
关键字with在不再需要访问文件后将其关闭
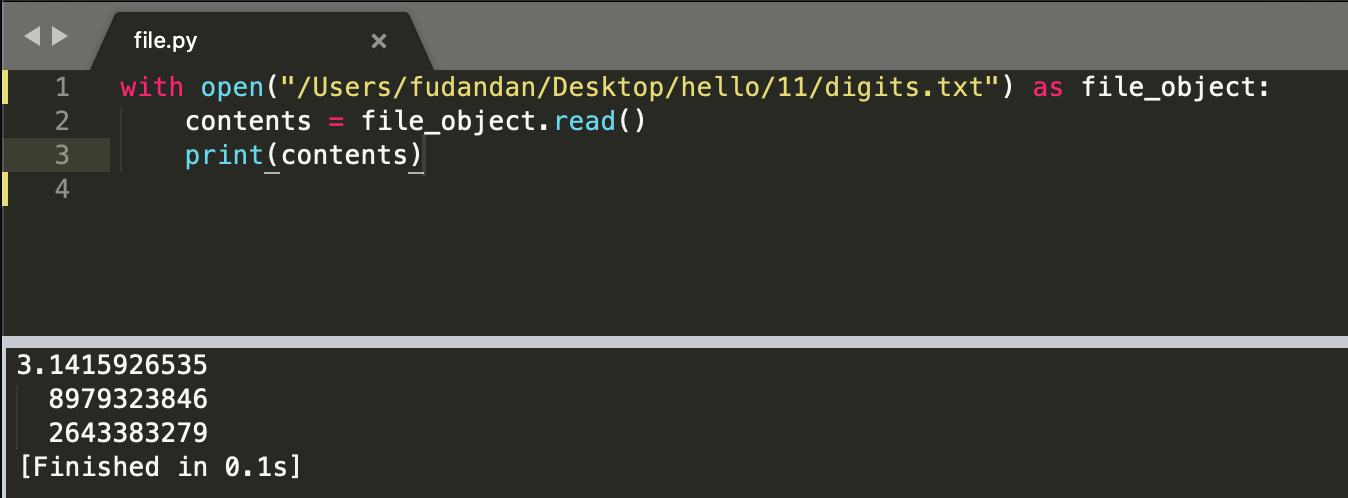
要让python打开不与程序文件位于同一目录中的文件,需要提供文件的路径,它让python到系统指定的位置去查找。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。