Python 3.6 中使用pdfminer解析pdf文件的实现
所使用python环境为最新的3.6版本
一、安装pdfminer模块
安装anaconda后,直接可以通过pip安装
pip install pdfminer3k
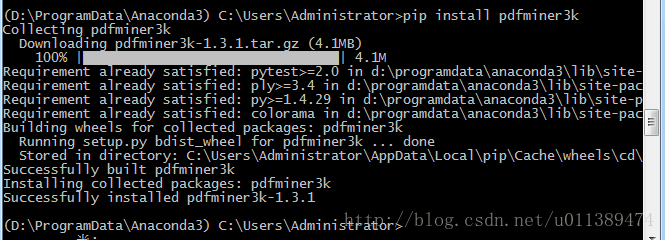
如上图所示安装成功。
二、在IDE中进行编码
#!/usr/bin/env python
# encoding: utf-8
"""
@author: wugang
@software: PyCharm
@file: prase_pdf.py
@time: 2017/3/3 0003 11:16
"""
import sys
import importlib
importlib.reload(sys)
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
'''
解析pdf 文本,保存到txt文件中
'''
path = r'../../data/pdf/阿里巴巴Java开发规范手册.pdf'
def parse():
fp = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(fp)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
with open(r'../../data/pdf/1.txt', 'a') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
parse()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。