python 多维高斯分布数据生成方式
我就废话不多说了,直接上代码吧!
import numpy as np
import matplotlib.pyplot as plt
def gen_clusters():
mean1 = [0,0]
cov1 = [[1,0],[0,10]]
data = np.random.multivariate_normal(mean1,cov1,100)
mean2 = [10,10]
cov2 = [[10,0],[0,1]]
data = np.append(data,
np.random.multivariate_normal(mean2,cov2,100),
0)
mean3 = [10,0]
cov3 = [[3,0],[0,4]]
data = np.append(data,
np.random.multivariate_normal(mean3,cov3,100),
0)
return np.round(data,4)
def save_data(data,filename):
with open(filename,'w') as file:
for i in range(data.shape[0]):
file.write(str(data[i,0])+','+str(data[i,1])+'\n')
def load_data(filename):
data = []
with open(filename,'r') as file:
for line in file.readlines():
data.append([ float(i) for i in line.split(',')])
return np.array(data)
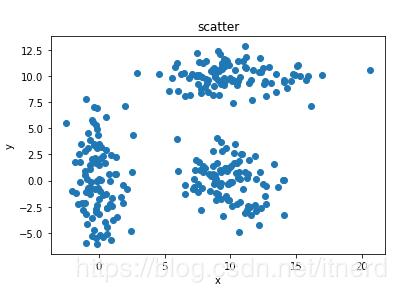
def show_scatter(data):
x,y = data.T
plt.scatter(x,y)
plt.axis()
plt.title("scatter")
plt.xlabel("x")
plt.ylabel("y")
data = gen_clusters()
save_data(data,'3clusters.txt')
d = load_data('3clusters.txt')
show_scatter(d)
以上这篇python 多维高斯分布数据生成方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。