Python实现word2Vec model过程解析
这篇文章主要介绍了Python实现word2Vec model过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
import gensim, logging, os
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
import nltk
corpus = nltk.corpus.brown.sents()
fname = 'brown_skipgram.model'
if os.path.exists(fname):
# load the file if it has already been trained, to save repeating the slow training step below
model = gensim.models.Word2Vec.load(fname)
else:
# can take a few minutes, grab a cuppa
model = gensim.models.Word2Vec(corpus, size=100, min_count=5, workers=2, iter=50)
model.save(fname)
words = "woman women man girl boy green blue".split()
for w1 in words:
for w2 in words:
print(w1, w2, model.similarity(w1, w2))
print(model.most_similar(positive=['woman', ''], topn=1))
print(model.similarity('woman', 'girl'))girl
在gensim模块中已经封装了13年提出的model--word2vec,所以我们直接开始建立模型
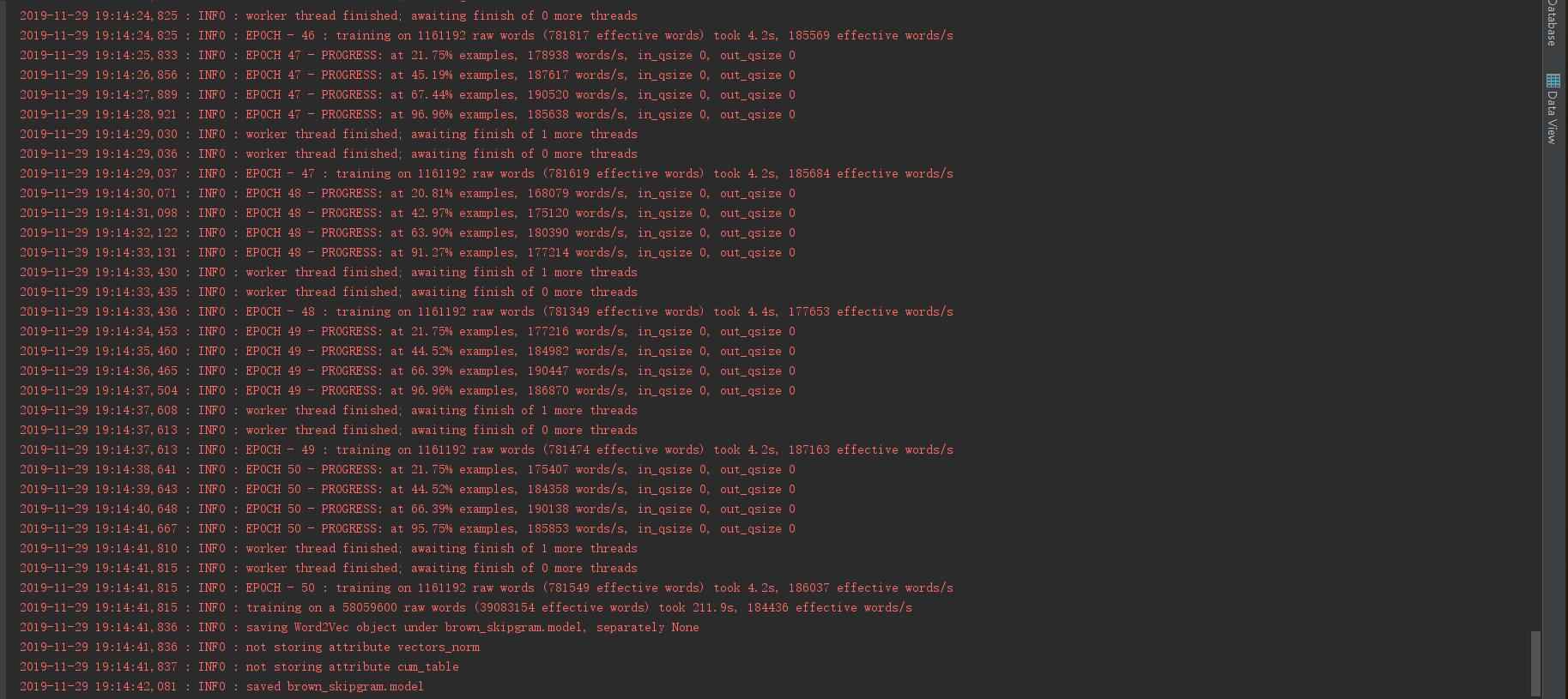
这是建立模型的过程,最后会出现saving Word2vec的语句,代表已经成功建立了模型

这是输入了 gorvement和news关键词后 所反馈的词语 --- administration, 他们之间的相关性是0.508
当我在输入 women 和 man ,他们显示的相关性的0.638 ,已经是非常高的一个数字。
值得一提的是,我用的语料库是直接从nltk里的brown语料库。其中大概包括了一些新闻之类的数据。
大家如果感兴趣的话,可以自己建立该模型,通过传入不同的语料库,来calc 一些term的 相关性噢
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。