Python实现序列化及csv文件读取
这篇文章主要介绍了Python实现序列化及csv文件读取,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
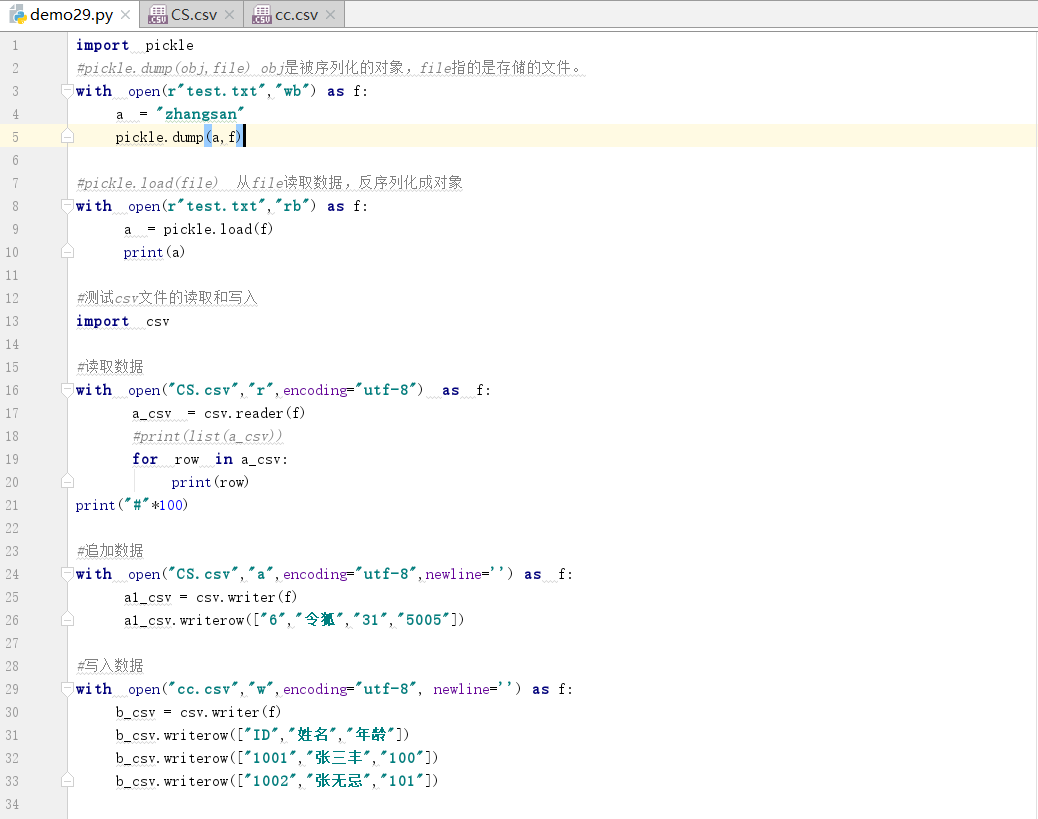
一、python 序列化:
序列化指的是将对象转化为"串行化"数据形式,存储到硬盘或通过网路传输到其他地方,反序列化是指相反的过程,将读取到串行化数据转化成对象。使用pickle模块中的函数,实现序列化和反序列化操作。
序列化使用:
pickle.dump(obj,file) obj是被序列化的对象,file指的是存储的文件。
pickle.load(file) 从file读取数据,反序列化成对象。
二、与execl 文件不同,csv文件中:
1.值没有类型,所有值都是字符串
2.不能指定字体颜色等样式
3.不能指定单元格的宽高、不能合并单元格
4.没有多个工作表
5.不能嵌入图像图表
示例:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
