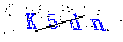yipeiwu_com6年前
现在有一批完整的关于介绍城市美食、景点等的html页面,需要将里面body的内容提取出来 方法:利用python插件beautifulSoup获取htmlbody标签的内容,并批量处理。...
yipeiwu_com6年前
如下所示: # coding = utf-8 import requests import json host = "http://47.XX.XX.XX:30000" endpo...
yipeiwu_com6年前
如下所示: filename=None if request.method == 'POST' and request.FILES.get('...
yipeiwu_com6年前
python的xpath没有获取div标签内html内容的功能,也就是获取div或a标签中的innerhtml,写了个小程序实现一下: 源代码 [webadmin@centos7 c...
yipeiwu_com6年前
div的内容为: <div style="background-color: rgb(255, 238, 221);" id="status" class="errors">...
yipeiwu_com6年前
今天用xpath获取的元素下面text 是被几个b标签分割开的,我想要一次性全部获取,参考了其他人的博客是如下的做法: value_ls = html.xpath("//tr/td[...
yipeiwu_com6年前
代码 使用方法见注释 #-*- coding: UTF-8 -*- from lxml import etree source = u''' <div><p c...
yipeiwu_com6年前
今天向大家总结一下python在做项目时用到的验证码生成工具:gvcode与captcha gvcode 全称:graphic-verification-code 安装: pip i...
yipeiwu_com6年前
在爬虫中遇见这种怎么办 想提取名称, 但是 名称不在一个标签里 使用xpath string()方法 例如 data.xpath("string(path)") path --...
yipeiwu_com6年前
如下所示: import os import re import string file = open("data2.txt") p1 = re.compile(r"^(\d...