php UTF-8、Unicode和BOM问题
一、介绍
UTF-8 是一种在web应用中经常使用的一种 Unicode 字符的编码方式,使用 UTF-8 的好处在于它是一种变长的编码方式,对于 ANSII 码编码长度为1个字节,这样的话在传输大量 ASCII 字符集的网页时,可以大量节约网络带宽。
UTF-8签名(UTF-8 signature)也叫做BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记。BOM,是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。微软做这种检测,但有些软件不做这种检测,而把它当作正常字符处理。微软在自己的UTF-8格式的文本文件之前加上了EF BB BF三个字节, windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的, 然而这个只是微软暗自作的标记, 其它平台上并没有对UTF-8文本文件做个这样的标记。也就是说一个UTF-8文件可能有BOM,也可能没有BOM。
只有一个BOM,是不会有问题的。如果多个文件设置了签名,在二进制流中就会包含多个UTF-8签名,也就是导致XML转换失败的"root element must be well-formed"原因。
二、查看和转换
既然一个UTF-8文件可能有BOM,也可能没有,那该如何区分呢?
只要用带十六进制编辑方式的软件,例如,用UltraEdit-32打开文件,切换到十六进制编辑模式,察看文件头部是否有EF BB BF。有,则为带BOM方式。
Windows自带的notepad记事本,保存为UTF-8时,默认就带BOM。
转换的方法有很多,常见的UltraEdit-32或NotePad++都可以,以UltraEdit-32为例。打开文件后,选择“另存为”,在“格式”一栏中有如下选择:
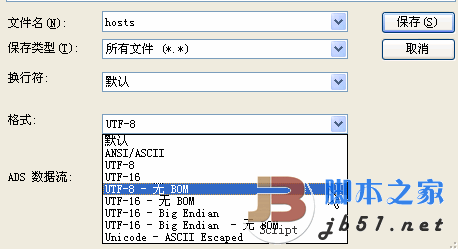
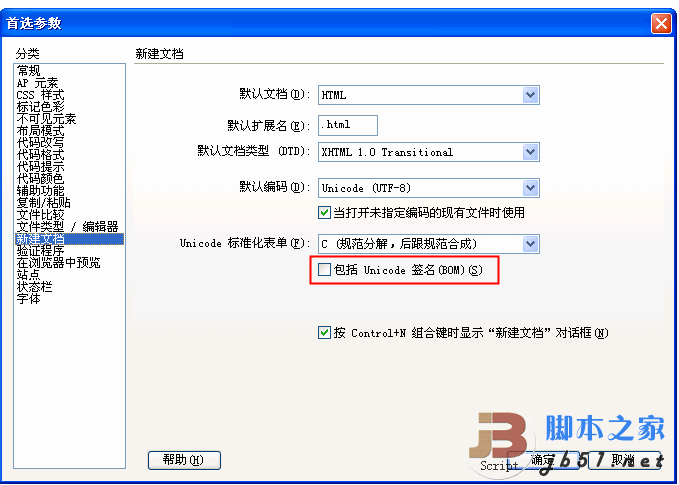
另外,DreamWeaver CS3也有类似的选项,在“首选项”中,如果选择 Unicode (UTF-8) 作为默认编码,则可以选择“包括 Unicode 签名 (BOM)”选项,以在文档中包括字节顺序标记 (BOM)。否则,不带BOM:
三、其他知识
从http://blog.csdn.net/thimin/archive/2007/08/03/1724393.aspx 一文了解到:
所谓的unicode保存的文件实际上是utf-16,只不过恰好跟unicode的码相同而已,但在概念上unicode与utf是两回事,unicode是内存编码表示方案,而utf是如何保存和传输unicode的方案。utf-16还分高位在前 (LE)和高位在后(BE)两种。官方的utf编码还有utf-32,也分LE和BE。非unicode官方的utf编码还有utf-7,主要用于邮件传输。utf-8的单字节部分是和iso-8859-1兼容的,这主要是一些旧的系统和库函数不能正确处理utf-16而被迫出来的,而且对英语字符来说,也节省保存的文件空间(以非英语字符浪费空间为代价)。在iso-8859-1的时候,utf8和iso-8859-1都是用一个字节表示的,当表示其它字符的时候,utf-8会使用两个或三个字节。
一段关于BOM的更详细说明,来自这里:
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
PHP也不支持BOM。
PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。由于必须在<?或者<?php后面的代码才会作为PHP代码执行,所以这三个字符将会直接输出。如果插件的文件有这个问题,将会导致在后台页面里激活或者不激活插件后显示白屏,如果是模版文件有这个问题,将会导致这三个字符直接输出,造成页面上方有一个小空行。国外的英文插件和模版一般都是用的ASCII码的编码方式,不会有BOM,只有国内的插件和模版会由于作者的不知情造成问题。还有,大家修改模版的时候,由于输出页面使用UTF-8编码,那么修改模版的时候如果有加入中文字符的话,必须把文件转成UTF-8编码才能正常显示,这个时候如果所使用的编辑器自动加上了BOM的话,将会造成在页面上输出这三个字符,显示效果就要看浏览器了,一般是一个空行或是一个乱码。
※ 补充一句:特别是当使用php导入模板的时候,更容易因为这三个字符,导致浏览异常。
UTF-8 是一种在web应用中经常使用的一种 Unicode 字符的编码方式,使用 UTF-8 的好处在于它是一种变长的编码方式,对于 ANSII 码编码长度为1个字节,这样的话在传输大量 ASCII 字符集的网页时,可以大量节约网络带宽。
UTF-8签名(UTF-8 signature)也叫做BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记。BOM,是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。微软做这种检测,但有些软件不做这种检测,而把它当作正常字符处理。微软在自己的UTF-8格式的文本文件之前加上了EF BB BF三个字节, windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的, 然而这个只是微软暗自作的标记, 其它平台上并没有对UTF-8文本文件做个这样的标记。也就是说一个UTF-8文件可能有BOM,也可能没有BOM。
只有一个BOM,是不会有问题的。如果多个文件设置了签名,在二进制流中就会包含多个UTF-8签名,也就是导致XML转换失败的"root element must be well-formed"原因。
二、查看和转换
既然一个UTF-8文件可能有BOM,也可能没有,那该如何区分呢?
只要用带十六进制编辑方式的软件,例如,用UltraEdit-32打开文件,切换到十六进制编辑模式,察看文件头部是否有EF BB BF。有,则为带BOM方式。
Windows自带的notepad记事本,保存为UTF-8时,默认就带BOM。
转换的方法有很多,常见的UltraEdit-32或NotePad++都可以,以UltraEdit-32为例。打开文件后,选择“另存为”,在“格式”一栏中有如下选择:
另外,DreamWeaver CS3也有类似的选项,在“首选项”中,如果选择 Unicode (UTF-8) 作为默认编码,则可以选择“包括 Unicode 签名 (BOM)”选项,以在文档中包括字节顺序标记 (BOM)。否则,不带BOM:
三、其他知识
从http://blog.csdn.net/thimin/archive/2007/08/03/1724393.aspx 一文了解到:
所谓的unicode保存的文件实际上是utf-16,只不过恰好跟unicode的码相同而已,但在概念上unicode与utf是两回事,unicode是内存编码表示方案,而utf是如何保存和传输unicode的方案。utf-16还分高位在前 (LE)和高位在后(BE)两种。官方的utf编码还有utf-32,也分LE和BE。非unicode官方的utf编码还有utf-7,主要用于邮件传输。utf-8的单字节部分是和iso-8859-1兼容的,这主要是一些旧的系统和库函数不能正确处理utf-16而被迫出来的,而且对英语字符来说,也节省保存的文件空间(以非英语字符浪费空间为代价)。在iso-8859-1的时候,utf8和iso-8859-1都是用一个字节表示的,当表示其它字符的时候,utf-8会使用两个或三个字节。
一段关于BOM的更详细说明,来自这里:
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
PHP也不支持BOM。
PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。由于必须在<?或者<?php后面的代码才会作为PHP代码执行,所以这三个字符将会直接输出。如果插件的文件有这个问题,将会导致在后台页面里激活或者不激活插件后显示白屏,如果是模版文件有这个问题,将会导致这三个字符直接输出,造成页面上方有一个小空行。国外的英文插件和模版一般都是用的ASCII码的编码方式,不会有BOM,只有国内的插件和模版会由于作者的不知情造成问题。还有,大家修改模版的时候,由于输出页面使用UTF-8编码,那么修改模版的时候如果有加入中文字符的话,必须把文件转成UTF-8编码才能正常显示,这个时候如果所使用的编辑器自动加上了BOM的话,将会造成在页面上输出这三个字符,显示效果就要看浏览器了,一般是一个空行或是一个乱码。
※ 补充一句:特别是当使用php导入模板的时候,更容易因为这三个字符,导致浏览异常。
