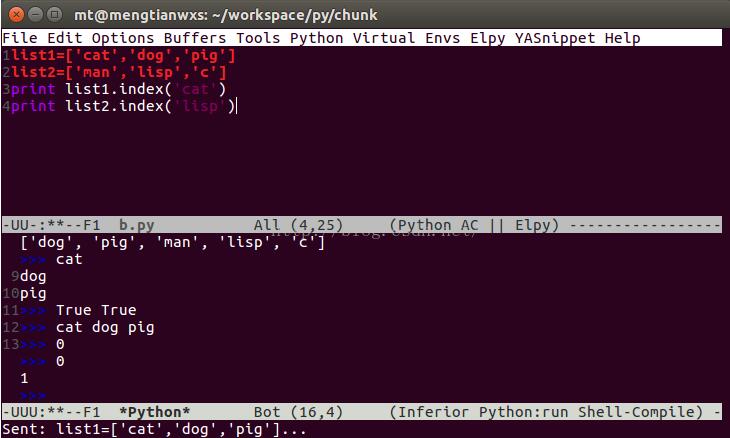
基于python的汉字转GBK码实现代码

如图,“广”的编码为%B9%E3,暂且把%B9称为节编码,%E3为字符编码(第二编码)。
思路:
从GBK编码页面收集汉字 http://ff.163.com/newflyff/gbk-list/
从实用角度下手,只选取“● GBK/2: GB2312 汉字”这一节,共3755个汉字。
看规律:小节编码从B0-D7,而针对汉字的编码从A1-FE,即16*6-2=94,非常有规律性。
第一步:把常用的汉字用python提取出来,按顺序存到一个字典文件里面,汉字用空格分隔。
第二步:根据编码从A1-FE,每节94个汉字的规律,先定位节编码,利用汉字在某一节的位置定位字符编码
实施:
第一步:提取汉字
复制代码 代码如下:
with open('E:/GBK.txt') as f:
s=f.read().splitlines().split()
分割得到的list里面有重复的节编码,要去掉B0/B1……类似的符号和中文的0-9/A-F字符
把获取到的字符解码看:


删除掉这些字符:
先把分割得到的list全部解码,然后
复制代码 代码如下:
gbk.remove(u'\uff10')
这里删除字符的时候,用range生成一系列字符串,然后用notepad++处理了一下,并没有找到简单的办法
复制代码 代码如下:
for t in [u'\uff10',u'\uff11',u'\uff12',u'\uff13',u'\uff14',u'\uff15',u'\uff16',u'\uff17',u'\uff18',u'\uff19',u'\uff21',u'\uff22',u'\uff23',u'\uff24',u'\uff25',u'\uff26']:
gbk.remove(t)
然后去除B0-D7这样的小节编码,同时提取字符编码的时候也要用到类似的A1-FE这样的编码,于是就想生成这样一个list,方便做删除和索引操作。
生成编码系列:
行编码为0-9 A-F,列编码为A-F
从A1开始递增,遇到边界(A9-AA)要手动处理,用到了ord()和chr()函数,在ASCII编码和数字之间转换。
复制代码 代码如下:
t=['A1']
while True:
if t[-1]=='FE':
break
if (ord(t[-1][1])>=48 and ord(t[-1][1])<57) or (ord(t[-1][1])>=65 and ord(t[-1][1])<70):
t.append(t[-1][0]+chr(ord(t[-1][1])+1))
continue
if ord(t[-1][1])>=57 and ord(t[-1][1])<65:
t.append(t[-1][0]+chr(65))
continue
if ord(t[-1][1])>=70:
t.append(chr(ord(t[-1][0])+1)+chr(48))
continue
得到的列表:

有了这个编码序列后,就可以从gbk库中删除B0-D7字符了。
最后检查到还有空格未删除,空格的unicode码是\u3000
gbk.remove(u'\u3000')
最后encode成UTF-8编码保存到字典文件。

我把这个字典文件放到网盘上了,外链:http://dl.dbank.com/c0m9selr6h
第二步:索引汉字
索引就是个简单算法,因为字典里面的汉子是按照原先顺序存储的,而且GBK编码表2的3755个汉字严格遵守每节94个汉字的规律,那就来个简单的除数取整+1来定位小节编码,再用汉字索引-节索引*94得到汉字在这一小节中的索引,然后利用上面生成的A1-FE list和索引来定位第二编码。
算法思路有了,编码,然后调试
附上python代码和注释:
复制代码 代码如下:
def getGBKCode(gbkFile='E:/GBK1.1.txt',s=''):
#gbkFile字典文件 共3755个汉字
#s为要转换的汉字,暂且为gb2312编码,即从IDLE输入的汉字编码
#读入字典
with open(gbkFile) as f:
gbk=f.read().split()
#生成A1-FE的索引编码
t=['A1']
while True:
if t[-1]=='FE':
break
if (ord(t[-1][1])>=48 and ord(t[-1][1])<57) or (ord(t[-1][1])>=65 and ord(t[-1][1])<70):
t.append(t[-1][0]+chr(ord(t[-1][1])+1))
continue
if ord(t[-1][1])>=57 and ord(t[-1][1])<65:
t.append(t[-1][0]+chr(65))
continue
if ord(t[-1][1])>=70:
t.append(chr(ord(t[-1][0])+1)+chr(48))
continue
#依次索引每个汉字
l=list()
for st in s.decode('gb2312'):
st=st.encode('utf-8')
i=gbk.index(st)+1
#小节编码从B0开始,获取汉字的小节编码
t1='%'+t[t.index('B0'):][i/94]
#汉字在节点中的索引号
i=i-(i/94)*94
t2='%'+t[i-1]
l.append(t1+t2)
#最后用空格分隔输出
return ' '.join(l)

得承认我的python代码不是那么工整
附上我的微博ID:小栾Cooper