Python实现获取网站PR及百度权重
上一次我用requests库写的一个抓取页面中链接的简单代码,延伸一下,我们还可以利用它来获取我们网站的PR以及百度权重。原理差不多。最后我们甚至可以写一个循环批量查询网站的相关信息。
先说说GooglePR,全称PageRank。它是Google官方给出的评定一个网站SEO的评级,这个大家应该不陌生。既然是官方给出的,当然有一个官方的接口去获取它。我们这里就利用官方的接口获取谷歌PR。
GPR_HASH_SEED ="Mining PageRank is AGAINST GOOGLE'S TERMS OF SERVICE. Y\
es, I'm talking to you, scammer."
def google_hash(value):
magic = 0x1020345
for i in xrange(len(value)):
magic ^= ord(GPR_HASH_SEED[i % len(GPR_HASH_SEED)]) ^ ord(value[i])
magic = (magic >> 23 | magic << 9) & 0xFFFFFFFF
return "8%08x" % (magic)
def getPR(www):
try:
url = 'http://toolbarqueries.google.com/tbr?' \
'client=navclient-auto&ch=%s&features=Rank&q=info:%s' % (google_hash(www) , www)
response = requests.get(url)
rex = re.search(r'(.*?:.*?:)(\d+)',response.text)
return rex.group(2)
except :
return None
使用方法:传入域名,返回PR值
google_hash这个函数只是个算法,算出一个域名类似hash值的一个东西并返回。可以不去管它是怎么实现的,我们主要看getPR这个函数。我们google官方给出的接口是这个:http://toolbarqueries.google.com/tbr?client=navclient-auto&ch={HASH}&features=Rank&q=info:{域名}
{HASH}这里我们就使用google_hash()这个函数,传入域名,返回它对应的HASH值。比如我们离别歌的域名www.leavesongs.com,它的谷歌HASH是8b1e6ad00,于是构造出来的咨询网址是:http://toolbarqueries.google.com/tbr?client=navclient-auto&ch=8b1e6ad00&features=Rank&q=info:www.leavesongs.com
访问它,得到Rank_1:1:0。第二个引号后面的数字是PR,因为我的站是没有PR的,所以PR为0.
于是,我们使用requests.get()来访问我们这个构造好的URL,然后获得类似Rank_1:1:0这样的结果,最后通过正则或其他方式得到PR值0。
以上是getPR这个函数的执行过程。再看获取百度权重的过程。
百度权重并不是百度官方给的一个标准,是一些第三方网站计算的一个值,所以并没有像PR一样的接口。所以我们就需要抓取这些第三方网站中的信息了。下面是获取百度权重的函数:
def getBR(www):
try:
url = 'http://mytool.chinaz.com/baidusort.aspx?host=%s&sortType=0' % ( www , )
response = requests.get(url)
data = response.text
rex = re.search(r'(<div class="siteinfo">.+?<font.+?>)(\d*?)(</font>)',data,re.I)
return rex.group(2)
except :
return None
使用方法也是传入域名,返回权重值。
我抓取的是站长工具的一个权重咨询的页面:http://mytool.chinaz.com/baidusort.aspx?host={域名}&sortType=0
我的正则就是它:(<div class="siteinfo">.+?<font.+?>)(\d*?)(</font>),大家可以自己查看源代码看一下,就知道正则怎么写了。
好了,我们来批量获取一下这些网站的PR和权重:
直接看结果:
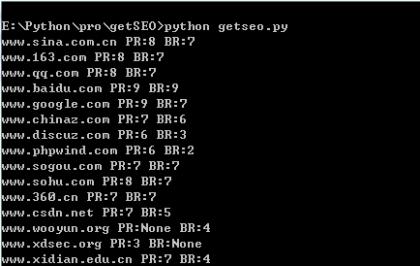
单一一个进程扫的话速度会略慢,开10个20个线程批量获取的话应该比较快。