Python实现的数据结构与算法之链表详解
本文实例讲述了Python实现的数据结构与算法之链表。分享给大家供大家参考。具体分析如下:
一、概述
链表(linked list)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接。
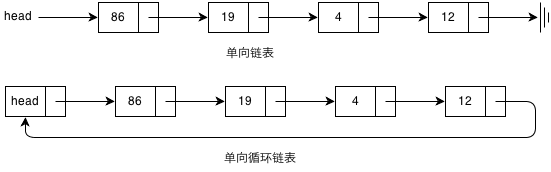
根据结构的不同,链表可以分为单向链表、单向循环链表、双向链表、双向循环链表等。其中,单向链表和单向循环链表的结构如下图所示:
二、ADT
这里只考虑单向循环链表ADT,其他类型的链表ADT大同小异。单向循环链表ADT(抽象数据类型)一般提供以下接口:
① SinCycLinkedlist() 创建单向循环链表
② add(item) 向链表中插入数据项
③ remove(item) 删除链表中的数据项
④ search(item) 在链表中查找数据项是否存在
⑤ empty() 判断链表是否为空
⑥ size() 返回链表中数据项的个数
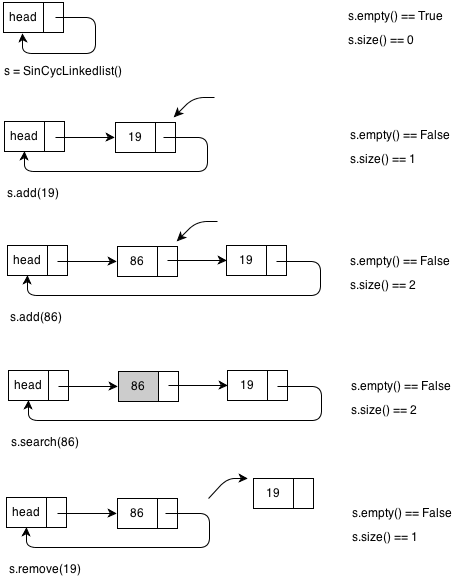
单向循环链表操作的示意图如下:
三、Python实现
Python的内建类型list底层是由C数组实现的,list在功能上更接近C++的vector(因为可以动态调整数组大小)。我们都知道,数组是连续列表,链表是链接列表,二者在概念和结构上完全不同,因此list不能用于实现链表。
在C/C++中,通常采用“指针+结构体”来实现链表;而在Python中,则可以采用“引用+类”来实现链表。在下面的代码中,SinCycLinkedlist类代表单向循环链表,Node类代表链表中的一个节点:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
class Node:
def __init__(self, initdata):
self.__data = initdata
self.__next = None
def getData(self):
return self.__data
def getNext(self):
return self.__next
def setData(self, newdata):
self.__data = newdata
def setNext(self, newnext):
self.__next = newnext
class SinCycLinkedlist:
def __init__(self):
self.head = Node(None)
self.head.setNext(self.head)
def add(self, item):
temp = Node(item)
temp.setNext(self.head.getNext())
self.head.setNext(temp)
def remove(self, item):
prev = self.head
while prev.getNext() != self.head:
cur = prev.getNext()
if cur.getData() == item:
prev.setNext(cur.getNext())
prev = prev.getNext()
def search(self, item):
cur = self.head.getNext()
while cur != self.head:
if cur.getData() == item:
return True
cur = cur.getNext()
return False
def empty(self):
return self.head.getNext() == self.head
def size(self):
count = 0
cur = self.head.getNext()
while cur != self.head:
count += 1
cur = cur.getNext()
return count
if __name__ == '__main__':
s = SinCycLinkedlist()
print('s.empty() == %s, s.size() == %s' % (s.empty(), s.size()))
s.add(19)
s.add(86)
print('s.empty() == %s, s.size() == %s' % (s.empty(), s.size()))
print('86 is%s in s' % ('' if s.search(86) else ' not',))
print('4 is%s in s' % ('' if s.search(4) else ' not',))
print('s.empty() == %s, s.size() == %s' % (s.empty(), s.size()))
s.remove(19)
print('s.empty() == %s, s.size() == %s' % (s.empty(), s.size()))
运行结果:
$ python sincyclinkedlist.py s.empty() == True, s.size() == 0 s.empty() == False, s.size() == 2 86 is in s 4 is not in s s.empty() == False, s.size() == 2 s.empty() == False, s.size() == 1
希望本文所述对大家的Python程序设计有所帮助。