以911新闻为例演示Python实现数据可视化的教程
本文介绍一个将911袭击及后续影响相关新闻文章的主题可视化的项目。我将介绍我的出发点,实现的技术细节和我对一些结果的思考。
简介
近代美国历史上再没有比911袭击影响更深远的事件了,它的影响在未来还会持续。从事件发生到现在,成千上万主题各异的文章付梓。我们怎样能利用数据科学的工具来探索这些主题,并且追踪它们随着时间的变化呢?
灵感
首先提出这个问题的是一家叫做Local Projects的公司,有人委任它们为纽约的国家911博物馆设置一个展览。他们的展览,Timescape,将事件的主题和文章可视化之后投影到博物馆的一面墙上。不幸的是,由于考虑到官僚主义的干预和现代人的三分钟热度,这个展览只能展现很多主题,快速循环播放。Timescape的设计给了我启发,但是我想试着更深入、更有交互性,让每个能接入互联网的人都能在空闲时观看。
这个问题的关键是怎么讲故事。每篇文章都有不同的讲故事角度,但是有线索通过词句将它们联系到一起。”Osama bin Laden”、 “Guantanamo Bay”、”Freedom”,还有更多词汇组成了我模型的砖瓦。
获取数据
所有来源当中,没有一个比纽约时报更适合讲述911的故事了。他们还有一个神奇的API,允许在数据库中查询关于某一主题的全部文章。我用这个API和其他一些Python网络爬虫以及NLP工具构建了我的数据集。
爬取过程是如下这样的:
- 调用API查询新闻的元数据,包括每篇文章的URL。
- 给每个URL发送GET请求,找到HTML中的正文文本,提取出来。
- 清理文章文本,去除停用词和标点
我写了一个Python脚本自动做这些事,并能够构建一个有成千上万文章的数据集。也许这个过程中最有挑战性的部分是写一个从HTML文档里提取正文的函数。近几十年来,纽约时报不时也更改了他们HTML文档的结构,所以这个抽取函数取决于笨重的嵌套条件语句:
# s is a BeautifulSoup object containing the HTML of the page
if s.find('p', {'itemprop': 'articleBody'}) is not None:
paragraphs = s.findAll('p', {'itemprop': 'articleBody'})
story = ' '.join([p.text for p in paragraphs])
elif s.find('nyt_text'):
story = s.find('nyt_text').text
elif s.find('div', {'id': 'mod-a-body-first-para'}):
story = s.find('div', {'id': 'mod-a-body-first-para'}).text
story += s.find('div', {'id': 'mod-a-body-after-first-para'}).text
else:
if s.find('p', {'class': 'story-body-text'}) is not None:
paragraphs = s.findAll('p', {'class': 'story-body-text'})
story = ' '.join([p.text for p in paragraphs])
else:
story = ''
文档向量化
在我们应用机器学习算法之前,我们要将文档向量化。感谢scikit-learn的IT-IDF Vectorizer模块,这很容易。只考虑单个词是不够的,因为我的数据集里并不缺一些重要的名字。所以我选择使用n-grams,n取了1到3。让人高兴的是,实现多个n-gram和实现单独关键词一样简单,只需要简单地设置一下Vectorizer的参数。
vec = TfidfVectorizer(max_features=max_features,
ngram_range=(1, 3),
max_df=max_df)
开始的模型里,我设置max_features(向量模型里词或词组的最大数量)参数为20000或30000,在我计算机的计算能力之内。但是考虑到我还加入了2-gram和3-gram,这些组合会导致特征数量的爆炸(这里面很多特征也很重要),在我的最终模型里我会提高这个数字。
用NMF做主题模型
非负矩阵分解(Non-negative Matrix Factorization,或者叫NMF),是一个线性代数优化算法。它最具魔力的地方在于不用任何阐释含义的先验知识,它就能提取出关于主题的有意义的信息。数学上它的目标是将一个nxm的输入矩阵分解成两个矩阵,称为W和H,W是nxt的文档-主题矩阵,H是txm的主题-词语矩阵。你可以发现W和H的点积与输入矩阵形状一样。实际上,模型试图构建W和H,使得他们的点积是输入矩阵的一个近似。这个算法的另一个优点在于,用户可以自主选择变量t的值,代表生成主题的数量。
再一次地,我把这个重要的任务交给了scikit-learn,它的NMF模块足够处理这个任务。如果我在这个项目上投入更多时间,我也许会找一些更高效的NMF实现方法,毕竟它是这个项目里最复杂耗时的过程。实现过程中我产生了一个主意,但没实现它,是一个热启动的问题。那样可以让用户用一些特定的词来填充H矩阵的行,从而在形成主题的过程中给系统一些领域知识。不管怎么样,我只有几周时间完成整个项目。还有很多其他的事需要我更多的精力。
主题模型的参数
因为主题模型是整个项目的基石,我在构建过程中做的决定对最终成果有很大影响。我决定输入模型的文章为911事件发生18个月以后的。在这个时间段喧嚣不再,所以这段时间出现的主题的确是911事件的直接结果。在向量化的阶段,开始几次运行的规模受限于我的计算机。20或者30个主题的结果还不错,但是我想要包含更多结果的更大模型。
我最终的模型使用了100000个向量词汇和大约15000篇文章。我设置了200个主题,所以NMF算法需要处理15000×100000, 15000×200和200×100000规模的矩阵。逐渐变换后两个矩阵来拟合第一个矩阵。
完成模型
最终模型矩阵完成之后,我查看每个主题并检查关键词(那些在主题-词语矩阵里有最高概率值的)。我给每个主题一个特定的名字(在可视化当中可以用),并决定是否保留这个主题。一些主题由于和中心话题无关被删除了(例如本地体育);还有一些太宽泛(关于股票市场或者政治的主题);还有一些太特定了,很可能是NMF算法的误差(一系列来源于同一篇文章中的有关联的3-grams)
这个过程之后我有了75个明确和相关的主题,每个都根据内容进行命名了。
分析
主题模型训练好之后,算出给定文章的不同主题的权重就很容易了:
- 使用存储的TF-IDF模型将文章文本向量化。
- 算出这个向量和精简过的NMF主题-词语矩阵的点积。(1x100k * 100k x 75 = 1 x 75 )
- 结果向量的75个维度表示这篇文章和75个主题有多相关。
更难的部分在于决定怎么把这些权重变成一个能讲故事的可视化的形式。如果我只是简单地将一段时期全部文章的话题权重加起来,这个分布应该是一个关于那段时间中每个主题出现频率的准确表达。但是,这个分布的组成部分对人类来说毫无意义。换种方式想,如果我对每个主题做一个二分分类,我就能算出一段时间内和一个主题相关的文章百分数。我选择了这个方法因为它更能说明问题。
话题二分分类也有难度,尤其是这么多文章和话题的情况下。一些文章在很多主题下都有更高的权重,因为他们比较长并且包含的关键词出现在不同主题里。其他一些文章在大多主题下权重都很低,即使人工判断都能发现它的确和某些主题相关。这些差别决定了固定权重阈值不是一个好的分类方法;一些文章属于很多主题而一些文章不属于任何主题。我决定将每篇文章分类到权重最高的三个主题下。尽管这个方法不完美,它还是能提供一个很好的平衡来解决我们主题模型的一些问题。
可视化
尽管数据获取,主题模型和分析阶段对这个项目都很重要,它们都是为最终可视化服务的。我努力平衡视觉吸引力和用户交互,让用户可以不需指导地探索和理解主题的趋势。我开始的图使用的是堆叠的区块,后来我意识到简单的线画出来就足够和清晰了。
我使用d3.js来做可视化,它对本项目数据驱动的模式来说正合适。数据本身被传到了网页上,通过一个包含主题趋势数据的CSV文件和两个包含主题和文章元数据的JSON文件。尽管我不是前端开发的专家,我还是成功地通过一周的课程学习了足够的d3,html和css知识,来构建一个令人满意的可视化页面。
一些有趣的主题
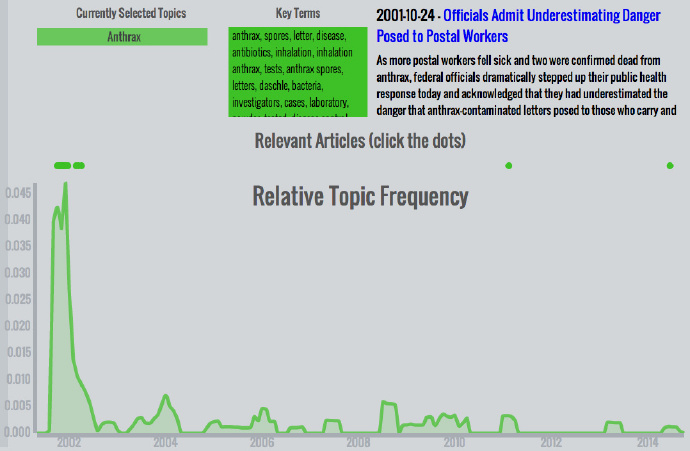
炭疽热 – 911以后,恐慌情绪笼罩全国。幸运的是,大部分恐慌都是多虑了。2001年晚期的炭疽热恐慌是一个没有什么后续影响的孤立事件,如图中清晰可见。
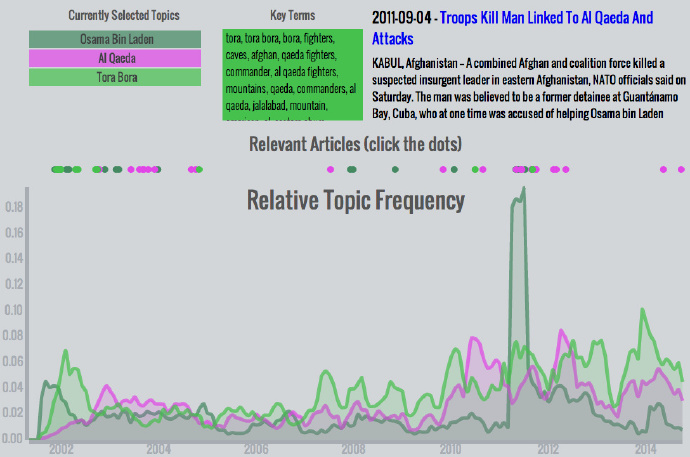
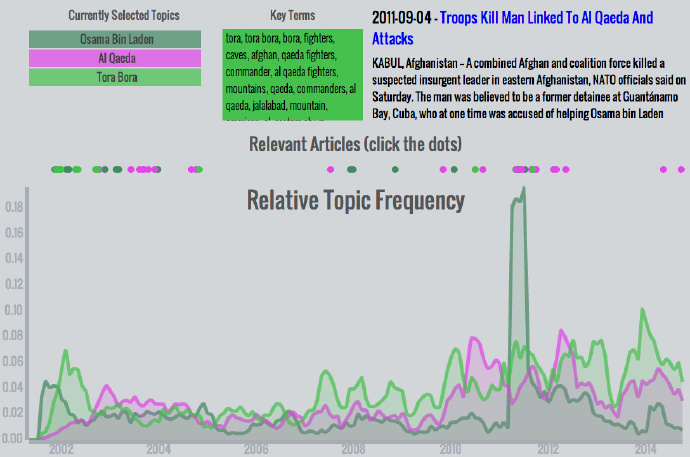
奥萨玛本拉登,基地组织,托拉博拉 – 所有主题中关注的峰值发生在本拉登2011年在阿伯塔巴德被打死之后。这个话题组合值得注意,因为它展现了911事件后媒体关注的演进:最开始,本拉登获得了很多关注。不久后,托拉博拉话题变得突出,因为托拉博拉是疑似本拉登的藏身地点和美军的关注重点。当本拉登逃脱了追捕,这两个话题的关注下降,而更宽泛的基地组织话题有些提升。近几年每个话题的逐渐提升说明了它们的关联性。尽管没有显著提升,它们相对的关注度还是在其他话题安静时有所提升。
我学到了什么
尽管我提出这个项目的时候就对主题模型和数据处理中的各个组分有了解,这个项目的真正意义在于它(再次)讲出的故事。911事件的本质是消极的,但是也有许多积极的故事:许多英雄救了很多人,社区融合,以及重建。
不幸的是,在我主题模型中展现出来这样的媒体环境:关注负能量、反派和破坏。当然,单独的一些英雄在一两篇文章中被赞扬了,但是没有一个足够广来形成一个主题。另一方面,像奥萨玛·本拉登和卡利亚·穆萨维这样的反派在很多文章中被提及。即使是理查德·里德,一个笨手笨脚的(试图)穿炸弹鞋炸飞机的人,都比一些成功的英雄有更持久的媒体影响(一个补充:注重词汇的主题模型的一个缺点就是,像Reid这样普通的名字会导致谈论不同人物的文章被聚集到一起。在这个例子里,哈利·里德和理查德·里德)。