相关文章
python3.7简单的爬虫实例详解
python3.7简单的爬虫,具体代码如下所示: #https://www.runoob.com/w3cnote/python-spider-intro.html #Python...
python爬虫 模拟登录人人网过程解析
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持 使用方法 1.实例化一个session对象 2.让session发送get或者post请求 sess...
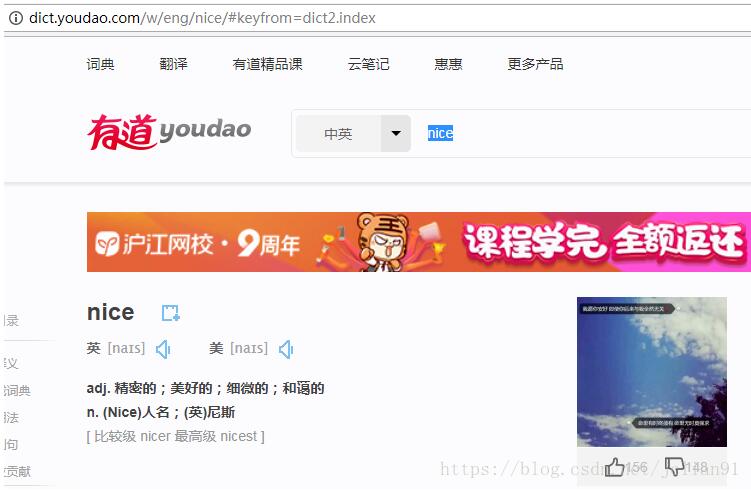
python爬虫之自制英汉字典
最近在微信公众号中看到有人用Python做了一个爬虫,可以将输入的英语单词翻译成中文,或者把中文词语翻译成英语单词。笔者看到了,觉得还蛮有意思的,因此,决定自己也写一个。 首先我们的爬虫...
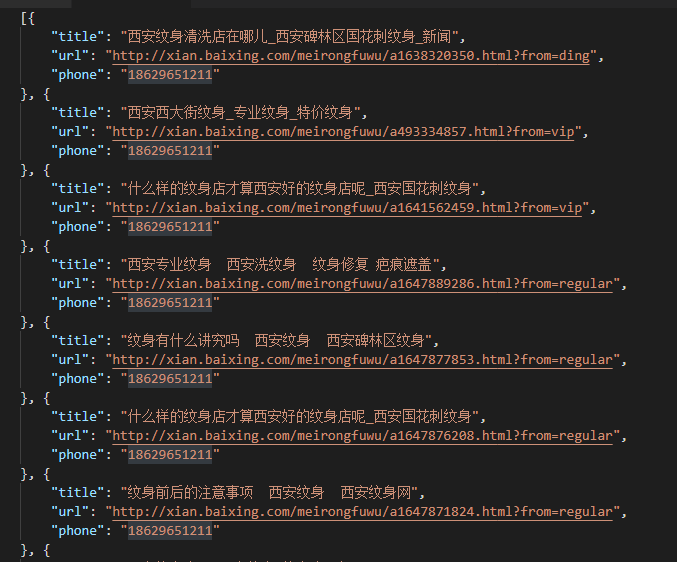
Python3爬虫爬取百姓网列表并保存为json功能示例【基于request、lxml和json模块】
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能。分享给大家供大家参考,具体如下: python3爬虫之爬取百姓网列表并保存为json文件。这几天一直在学习使用pyth...

python面向对象多线程爬虫爬取搜狐页面的实例代码
首先我们需要几个包:requests, lxml, bs4, pymongo, redis 1. 创建爬虫对象,具有的几个行为:抓取页面,解析页面,抽取页面,储存页面 class S...