安装ElasticSearch搜索工具并配置Python驱动的方法
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。
Elasticsearch 是开源搜索平台的新成员,实时数据分析的神器,发展迅猛,基于 Lucene、RESTful、分布式、面向云计算设计、实时搜索、全文搜索、稳定、高可靠、可扩展、安装+使用方便,介绍都说的很好听,好不好用拿出来遛一遛。
做了个简单测试,在两台完全一样的虚拟机上,2000万条左右数据,Elasticsearch 插入数据速度比 MongoDB 慢很多(可以忍受),但是搜索/查询速度快10倍以上,这只是单机情况,多机集群情况下 Elasticsearch 表现更好一些。以下安装步骤在 Ubuntu Server 14.04 LTS 上完成。
安装 Elasticsearch
升级系统后安装 Oracle Java 7,既然 Elasticsearch 官方推荐使用 Oracle JDK 7 就不要尝试 JDK 8 和 OpenJDK 了:
$ sudo apt-get update $ sudo apt-get upgrade $ sudo apt-get install software-properties-common $ sudo add-apt-repository ppa:webupd8team/java $ sudo apt-get update $ sudo apt-get install oracle-java7-installer
加入 Elasticsearch 官方源后安装 elasticsearch:
$ wget -O - http://packages.elasticsearch.org/GPG-KEY-elasticsearch | apt-key add - $ sudo echo "deb http://packages.elasticsearch.org/elasticsearch/1.1/debian stable main" >> /etc/apt/sources.list $ sudo apt-get update $ sudo apt-get install elasticsearch
加入到系统启动文件并启动 elasticsearch 服务,用 curl 测试一下安装是否成功:
$ sudo update-rc.d elasticsearch defaults 95 1
$ sudo /etc/init.d/elasticsearch start
$ curl -X GET 'http://localhost:9200'
{
"status" : 200,
"name" : "Fer-de-Lance",
"version" : {
"number" : "1.1.1",
"build_hash" : "f1585f096d3f3985e73456debdc1a0745f512bbc",
"build_timestamp" : "2014-04-16T14:27:12Z",
"build_snapshot" : false,
"lucene_version" : "4.7"
},
"tagline" : "You Know, for Search"
}
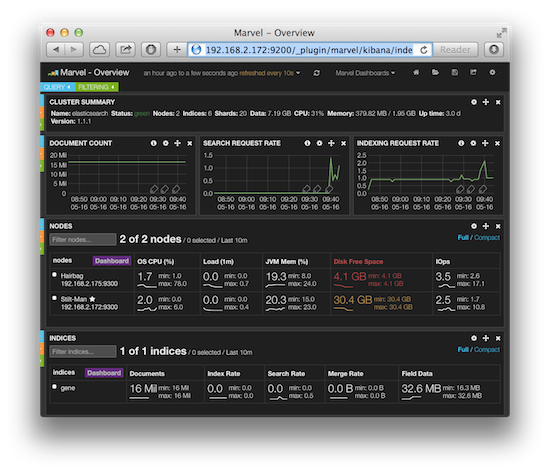
Elasticsearch 的集群和数据管理界面 Marvel 非常赞,可惜只对开发环境免费,如果这个工具也免费就无敌了,安装很简单,完成后重启服务访问 http://192.168.2.172:9200/_plugin/marvel/ 就可以看到界面:
$ sudo /usr/share/elasticsearch/bin/plugin -i elasticsearch/marvel/latest $ sudo /etc/init.d/elasticsearch restart * Stopping Elasticsearch Server [ OK ] * Starting Elasticsearch Server [ OK ]
安装 Python 客户端驱动
和 MongoDB 一样,我们一般用程序和 Elasticsearch 交互,Elasticsearch 也支持多种语言的客户端驱动,这里仅安装 Python 驱动,其他语言可以参考官方文档。
$ sudo apt-get install python-pip $ sudo pip install elasticsearch
写个简单程序把 gene_info.txt 的数据导入到 Elasticsearch:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os, os.path, sys, re
import csv, time, string
from datetime import datetime
from elasticsearch import Elasticsearch
def import_to_db():
data = csv.reader(open('gene_info.txt', 'rb'), delimiter='\t')
data.next()
es = Elasticsearch()
for row in data:
doc = {
'tax_id': row[0],
'GeneID': row[1],
'Symbol': row[2],
'LocusTag': row[3],
'Synonyms': row[4],
'dbXrefs': row[5],
'chromosome': row[6],
'map_location': row[7],
'description': row[8],
'type_of_gene': row[9],
'Symbol_from_nomenclature_authority': row[10],
'Full_name_from_nomenclature_authority': row[11],
'Nomenclature_status': row[12],
'Other_designations': row[13],
'Modification_date': row[14]
}
res = es.index(index="gene", doc_type='gene_info', body=doc)
def main():
import_to_db()
if __name__ == "__main__":
main()
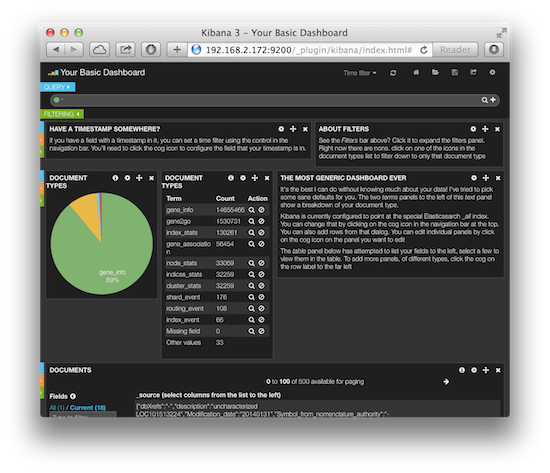
Kibana 是一个功能强大的数据显示客户端,通过插件方式和 Elasticsearch 集成在一起,安装很容易,下载解压就可以了,然后重启 Elasticsearch 服务访问 http://192.168.2.172:9200/_plugin/kibana/ 就能看到界面:
$ wget https://download.elasticsearch.org/kibana/kibana/kibana-3.0.1.tar.gz $ tar zxvf kibana-3.0.1.tar.gz $ sudo mv kibana-3.0.1 /usr/share/elasticsearch/plugins/_site $ sudo /etc/init.d/elasticsearch restart