如何使用python爬取csdn博客访问量
最近学习了python和爬虫,想写一个程序练练手,所以我就想到了大家都比较关心的自己的博客访问量,使用python来获取自己博客的访问量,这也是后边我将要进行的项目的一部分,后边我会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问的情况,使自己能更加清楚自己的哪些博客更受关注,博客专家请勿喷,因为我不是专家,我听他们说专家本身就有这个功能。
一、网址分析
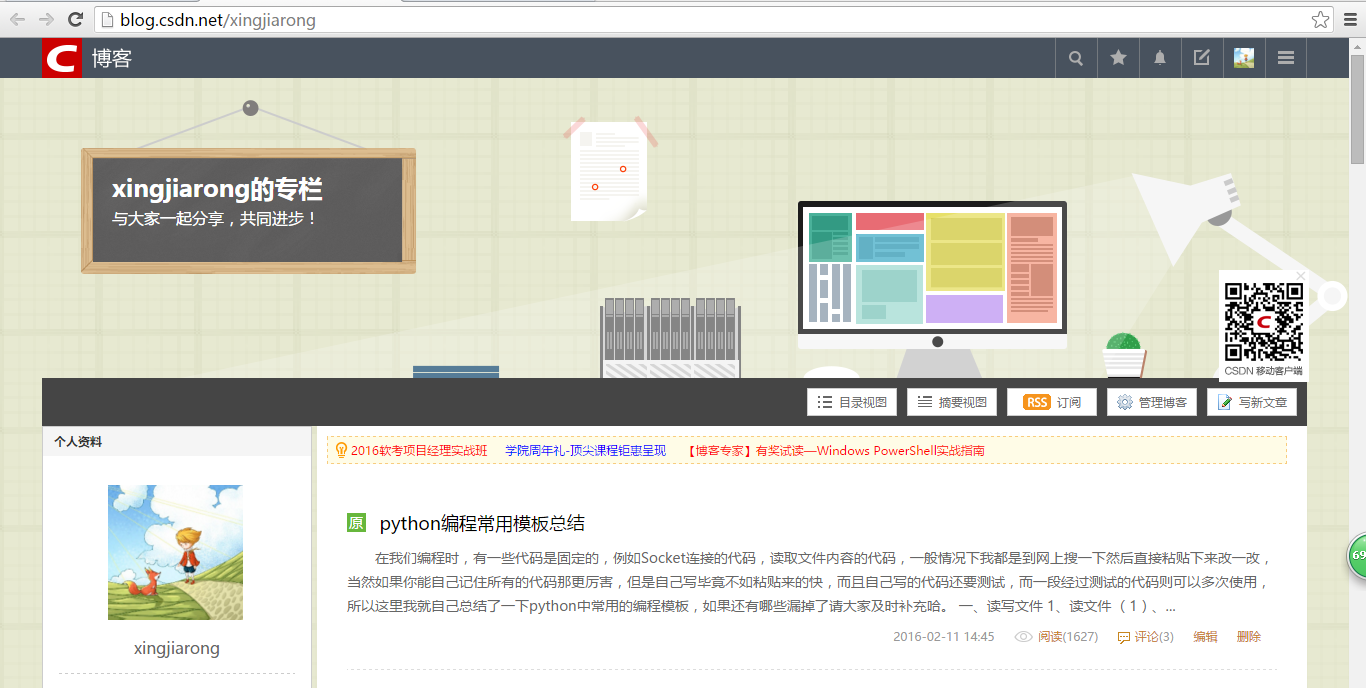
进入自己的博客页面,网址为:http://blog.csdn.net/xingjiarong 网址还是非常清晰的就是csdn的网址+个人csdn登录账号,我们来看一下下一页的网址。
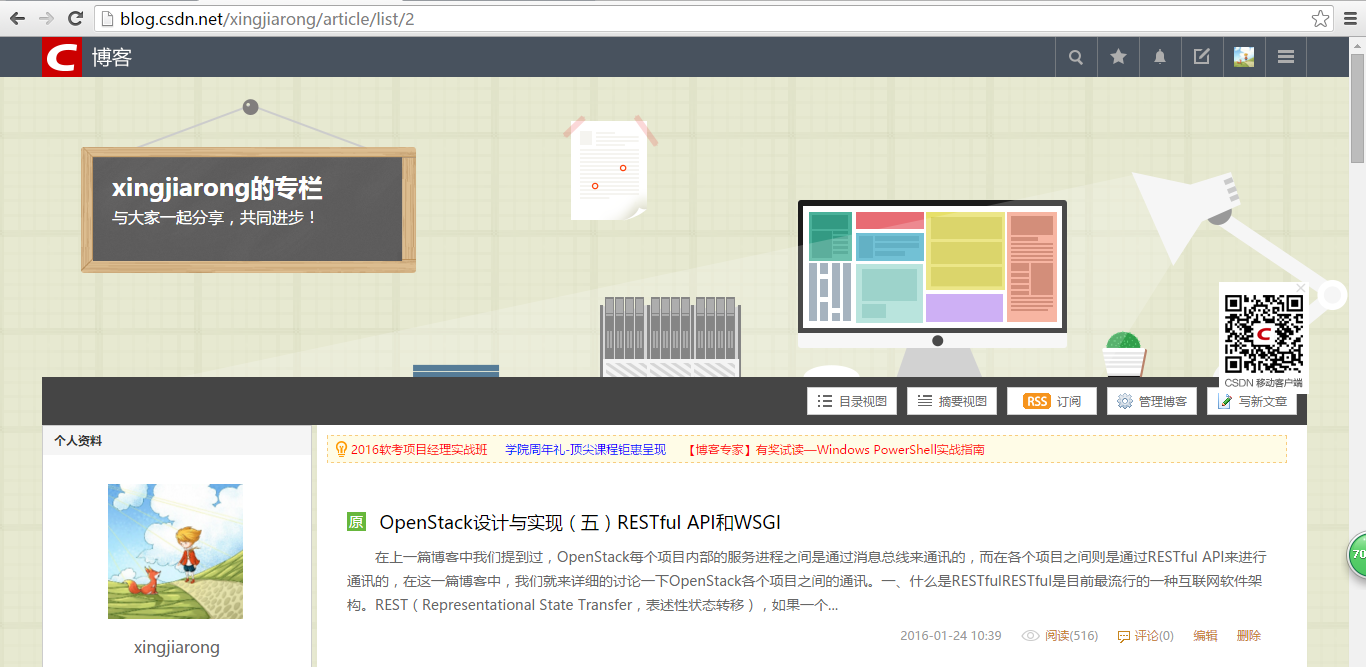
看到第二页的地址为:http://blog.csdn.net/xingjiarong/article/list/2
后边的数字表示现在正处于第几页,再用其他的页面验证一下,确实是这样的,那么第一页为什么不是http://blog.csdn.net/xingjiarong/article/list/1呢,那么我们在浏览器中输入http://blog.csdn.net/xingjiarong/article/list/1试试,哎,果然是第一页啊,其实第一页是被重定向了,http://blog.csdn.net/xingjiarong被重定向到http://blog.csdn.net/xingjiarong/article/list/1,所以两个网址都能访问第一页,那么现在规律就非常明显了:
http://blog.csdn.net/xingjiarong/article/list/ + 页号
二、如何获取标题
右键查看网页的源代码,我们看到可以找到这样一段代码:
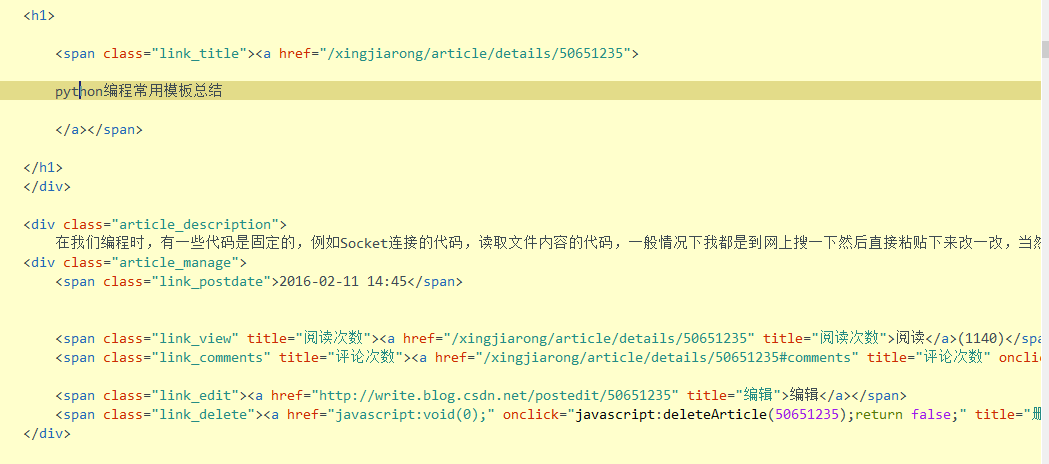
我们可以看到标题都是在标签
<span class="link_title"><a href="/xingjiarong/article/details/50651235">
所以我们可以使用下面的正则表达式来匹配标题:
<span class="link_title"><a href=".*?">(.*?)</a></span>
三、如何获取访问量
拿到了标题之后,就要获得对应的访问量了,经过对源码的分析,我看到访问量的结构都是这样的:
<span class="link_view" title="阅读次数"> <a href="/xingjiarong/article/details/50651235" title="阅读次数">阅读</a>(1140)</span>
括号中的数字即为访问量,我们可以用下面的正则表达式来匹配:
<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>
四、如何判断是否为尾页
接下来我们要判断当前页是否为最后一页,否则我们就不能判断什么时候结束了,我找到了源码中‘尾页'的标签,发现是下面的结构:
<a href="/xingjiarong/article/list/2">下一页</a> <a href="/xingjiarong/article/list/7">尾页</a>
所以我们可以用下面的正则表达式来匹配,如果匹配成功就说明当前页不是最后一页,否则当前页就是最后一页。
<a href=".*?">尾页</a>
五、编程实现
下面是完整的代码实现:
#!usr/bin/python
# -*- coding: utf-8 -*-
'''
Created on 2016年2月13日
@author: xingjiarong
使用python爬取csdn个人博客的访问量,主要用来练手
'''
import urllib2
import re
#当前的博客列表页号
page_num = 1
#不是最后列表的一页
notLast = 1
account = str(raw_input('输入csdn的登录账号:'))
while notLast:
#首页地址
baseUrl = 'http://blog.csdn.net/'+account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+'/article/list/'+str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent}
#构造请求
req = urllib2.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
#在页面中查找是否存在‘尾页'这一个标签来判断是否为最后一页
notLast = re.findall('<a href=".*?">尾页</a>',myPage,re.S)
print '-----------------------------第%d页---------------------------------' % (page_num,)
#利用正则表达式来获取博客的标题
title = re.findall('<span class="link_title"><a href=".*?">(.*?)</a></span>',myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items).lstrip().rstrip())
#利用正则表达式获取博客的访问量
view = re.findall('<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>',myPage,re.S)
viewList=[]
for items in view:
viewList.append(str(items).lstrip().rstrip())
#将结果输出
for n in range(len(titleList)):
print '访问量:%s 标题:%s' % (viewList[n].zfill(4),titleList[n])
#页号加1
page_num = page_num + 1
下面是部分结果:
输入csdn的登录账号:xingjiarong -----------------------------第1页--------------------------------- 访问量:1821 标题:python编程常用模板总结 访问量:1470 标题:设计模式之UML(一)类图以及类间关系(泛化 、实现、依赖、关联、聚合、组合) 访问量:0714 标题:ubuntu14.04 安装并破解MyEclipse2014 访问量:1040 标题:ubuntu14.04 配置tomcat8 访问量:1355 标题:java调用python方法总结 访问量:0053 标题:Java多线程之Callable和Future 访问量:1265 标题:跟我学汇编(三)寄存器和物理地址的形成 访问量:1083 标题:跟我学汇编(二)王爽汇编环境搭建 访问量:0894 标题:跟我学汇编(一)基础知识 访问量:2334 标题:java多线程(一)Race Condition现象及产生的原因 访问量:0700 标题:Matlab矩阵基础 访问量:0653 标题:Matlab变量、分支语句和循环语句 访问量:0440 标题:Matlab字符串处理 访问量:0514 标题:Matlab运算符与运算 访问量:0533 标题:Matlab的数据类型 -----------------------------第2页--------------------------------- 访问量:0518 标题:OpenStack设计与实现(五)RESTful API和WSGI 访问量:0540 标题:解决Android SDK Manager下载太慢问题 访问量:0672 标题:OpenStack设计与实现(四)消息总线(AMQP) 访问量:0570 标题:分布式文件存储FastDFS(五)FastDFS常用命令总结 访问量:0672 标题:分布式文件存储FastDFS(四)配置fastdfs-apache-module 访问量:0979 标题:分布式文件存储FastDFS(一)初识FastDFS 访问量:0738 标题:分布式文件存储FastDFS(三)FastDFS配置 访问量:0682 标题:分布式文件存储FastDFS(二)FastDFS安装 访问量:0511 标题:OpenStack设计与实现(三)KVM和QEMU浅析 访问量:0593 标题:OpenStack设计与实现(二)Libvirt简介与实现原理 访问量:0562 标题:OpenStack设计与实现(一)虚拟化 访问量:0685 标题:食堂买饭的启示 访问量:0230 标题:UML之时序图详解 访问量:0890 标题:设计模式之桥梁模式和策略模式的区别 访问量:1258 标题:设计模式(十二)责任链模式
总结:
使用python编写爬虫,我个人总结了以下的步骤:
1、分析要抓取的网址特征,以确定如何生成相关网页的网址,如果只爬取一个网页,则这一步可以省略。
2、查看网页的源码,分析自己想要爬取的内容所在的标签的特征。
3、使用正则表达式从源码中将自己想要的部分抠出来。
4、编程实现。
以上内容是针对如何使用python爬取csdn博客访问量的相关知识,希望对大家有所帮助。