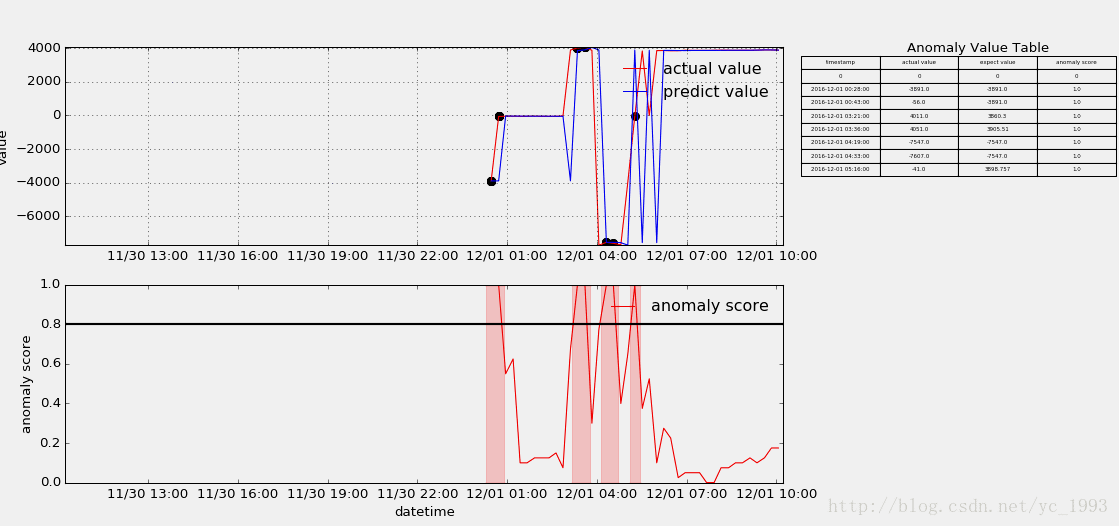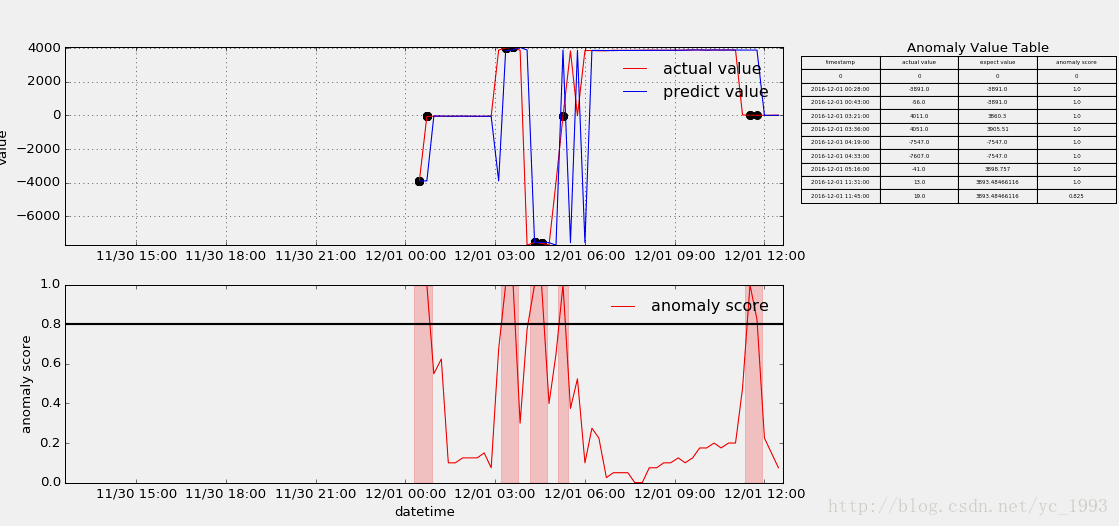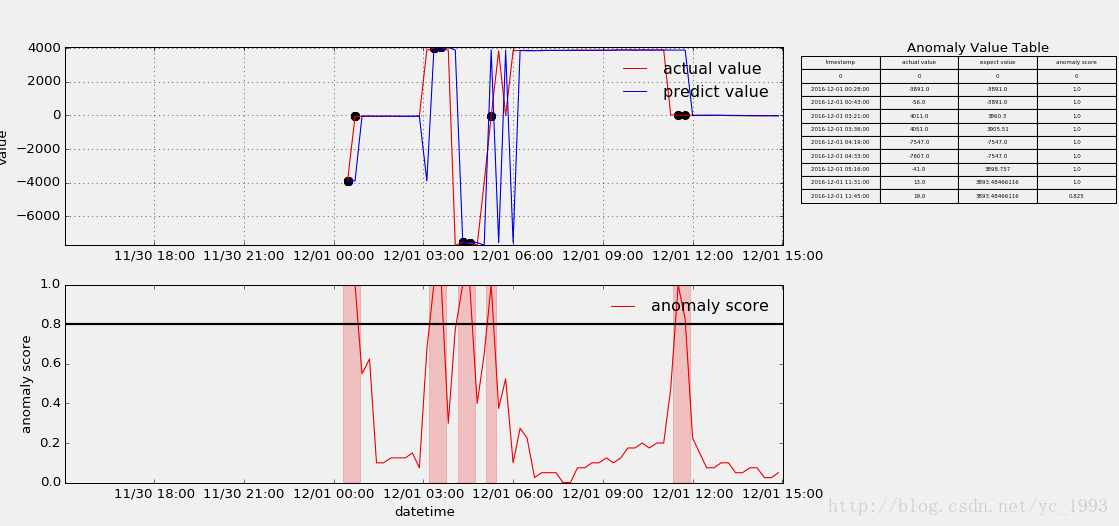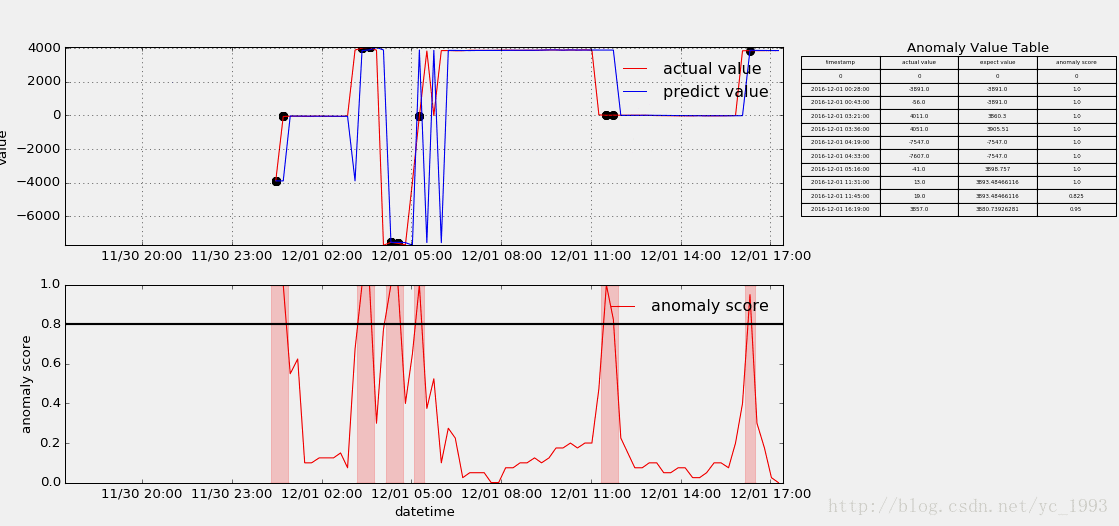
举例简单讲解Python中的数据存储模块shelve的用法
shelve类似于一个key-value数据库,可以很方便的用来保存Python的内存对象,其内部使用pickle来序列化数据,简单来说,使用者可以将一个列表、字典、或者用户自定义的类实例保存到shelve中,下次需要用的时候直接取出来,就是一个Python内存对象,不需要像传统数据库一样,先取出数据,然后用这些数据重新构造一遍所需要的对象。下面是简单示例:
import shelve
def test_shelve():
# open 返回一个Shelf类的实例
#
# 参数flag的取值范围:
# 'r':只读打开
# 'w':读写访问
# 'c':读写访问,如果不存在则创建
# 'n':读写访问,总是创建新的、空的数据库文件
#
# protocol:与pickle库一致
# writeback:为True时,当数据发生变化会回写,不过会导致内存开销比较大
d = shelve.open('shelve.db', flag='c', protocol=2, writeback=False)
assert isinstance(d, shelve.Shelf)
# 在数据库中插入一条记录
d['abc'] = {'name': ['a', 'b']}
d.sync()
print d['abc']
# writeback是False,因此对value进行修改是不起作用的
d['abc']['x'] = 'x'
print d['abc'] # 还是打印 {'name': ['a', 'b']}
# 当然,直接替换key的value还是起作用的
d['abc'] = 'xxx'
print d['abc']
# 还原abc的内容,为下面的测试代码做准备
d['abc'] = {'name': ['a', 'b']}
d.close()
# writeback 为 True 时,对字段内容的修改会writeback到数据库中。
d = shelve.open('shelve.db', writeback=True)
# 上面我们已经保存了abc的内容为{'name': ['a', 'b']},打印一下看看对不对
print d['abc']
# 修改abc的value的部分内容
d['abc']['xx'] = 'xxx'
print d['abc']
d.close()
# 重新打开数据库,看看abc的内容是否正确writeback
d = shelve.open('shelve.db')
print d['abc']
d.close()
这个有一个潜在的小问题,如下:
>>> import shelve
>>> s = shelve.open('test.dat')
>>> s['x'] = ['a', 'b', 'c']
>>> s['x'].append('d')
>>> s['x']
['a', 'b', 'c']
存储的d到哪里去了呢?其实很简单,d没有写回,你把['a', 'b', 'c']存到了x,当你再次读取s['x']的时候,s['x']只是一个拷贝,而你没有将拷贝写回,所以当你再次读取s['x']的时候,它又从源中读取了一个拷贝,所以,你新修改的内容并不会出现在拷贝中,解决的办法就是,第一个是利用一个缓存的变量,如下所示
>>> temp = s['x']
>>> temp.append('d')
>>> s['x'] = temp
>>> s['x']
['a', 'b', 'c', 'd']
在python2.4以后有了另外的方法,就是把open方法的writeback参数的值赋为True,这样的话,你open后所有的内容都将在cache中,当你close的时候,将全部一次性写到硬盘里面。如果数据量不是很大的时候,建议这么做。
下面是一个基于shelve的简单数据库的代码
#database.py
import sys, shelve
def store_person(db):
"""
Query user for data and store it in the shelf object
"""
pid = raw_input('Enter unique ID number: ')
person = {}
person['name'] = raw_input('Enter name: ')
person['age'] = raw_input('Enter age: ')
person['phone'] = raw_input('Enter phone number: ')
db[pid] = person
def lookup_person(db):
"""
Query user for ID and desired field, and fetch the corresponding data from
the shelf object
"""
pid = raw_input('Enter ID number: ')
field = raw_input('What would you like to know? (name, age, phone) ')
field = field.strip().lower()
print field.capitalize() + ':', \
db[pid][field]
def print_help():
print 'The available commons are: '
print 'store :Stores information about a person'
print 'lookup :Looks up a person from ID number'
print 'quit :Save changes and exit'
print '? :Print this message'
def enter_command():
cmd = raw_input('Enter command (? for help): ')
cmd = cmd.strip().lower()
return cmd
def main():
database = shelve.open('database.dat')
try:
while True:
cmd = enter_command()
if cmd == 'store':
store_person(database)
elif cmd == 'lookup':
lookup_person(database)
elif cmd == '?':
print_help()
elif cmd == 'quit':
return
finally:
database.close()
if __name__ == '__main__': main()