实例解析Python的Twisted框架中Deferred对象的用法
Deferred对象结构
Deferred由一系列成对的回调链组成,每一对都包含一个用于处理成功的回调(callbacks)和一个用于处理错误的回调(errbacks)。初始状态下,deffereds将由两个空回调链组成。在向其中添加回调时将总是成对添加。当异步处理中的结果返回时,Deferred将会启动并以添加时的顺序触发回调链。
用实例也许更容易说明,首先来看看addCallback:
from twisted.internet.defer import Deferred
def myCallback(result):
print result
d = Deferred()
d.addCallback(myCallback)
d.callback("Triggering callback.")
运行它将会得到如下结果:
Triggering callback.
上例中创建了一个deffered并利用其addCallback方法注册一个用于处理成功的回调。d.callback会启动deffered并调用callback链。传入callback的参数也会被各callback链中的第一个函数接收到。
有addCallback,那另一个错误的分支,我想也能猜测到了那就是addErrorback,同样来看个例子:
from twisted.internet.defer import Deferred
def myErrback(failure):
print failure
d = Deferred()
d.addErrback(myErrback)
d.errback(ValueError("Triggering errback."))
运行它将会得到如下结果:
[Failure instance: Traceback (failure with no frames): <type 'exceptions.ValueError'>: Triggering errback.]
可以看出Twisted会把错误封装在Failure里。
值得注意的是,在之前提到过注册回调总是成对的。在使用d.addCallback和d.addErrorback方法时,我们看似只是添加了一个callback或一个errback。而实际上,为了完成这一级回调链的创建,这些方法还会为另一半注册一个pass-through。要记住,回调链总是具有相同的长度。如果要分别指定这一级回调的callback和errback。可以使用d.addCallbacks方法:
d = Deferred()
d.addCallbacks(myCallback, myErrback)
d.callback("Triggering callback.")
进阶示例
接下来就应该来点更为实际的,那就是放进Reactor。先来看一个例子:
from twisted.internet import reactor, defer
class HeadlineRetriever(object):
def processHeadline(self, headline):
if len(headline) > 50:
self.d.errback(Exception("The headline ``%s'' is too long!" % (headline,)))
else:
self.d.callback(headline)
def _toHTML(self, result):
return "<h1>%s</h1>" % (result,)
def getHeadline(self, input):
self.d = defer.Deferred()
reactor.callLater(1, self.processHeadline, input)
self.d.addCallback(self._toHTML)
return self.d
def printData(result):
print result
reactor.stop()
def printError(failure):
print failure
reactor.stop()
h = HeadlineRetriever()
d = h.getHeadline("Breaking News: Twisted Takes us to the Moon!")
d.addCallbacks(printData, printError)
reactor.run()
上例接收一个标题并对其进行处理,如果标题超长会返回超长的错误,否则将其转为HTML并返回。
因所给的标题少于50个字符,故执行以上代码会得到如下返回:
<h1>Breaking News: Twisted Takes us to the Moon!</h1>
有一点值得注意的,上面用到了reactor的callLater方法,它可以用来做定时事件从而模拟一个异步的请求。
如果我们将标题变得很长,比如说:
h = HeadlineRetriever()
d = h.getHeadline("1234567890"*6)
d.addCallbacks(printData, printError)
那结果是可以遇见的:
[Failure instance: Traceback (failure with no frames): <type 'exceptions.Exception'>: The headline ``123456789012345678901234567890123456789012345678901234567890'' is too long!]
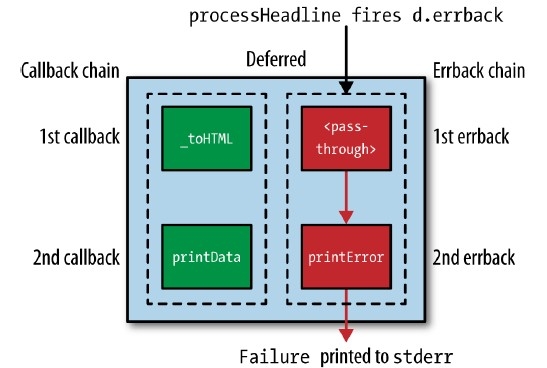
Deferreds中的关键之处
1. Deferreds将会在调用其callback或errback时被触发;
2. Deferreds仅能被触发一次!如果尝试多次触发将会导致AlreadyCalledError异常;
3. 第N级callback或errback中的Exceptions将会传入第N+1级的errback中;如果没有errback,则会抛出Unhandled Error。如果第N级callback或errback中没有抛出Exception或返回Failure对象,那接下来将会由第N+1级中的callback进行处理;
4. callback中返回的结果将会传入下一级callback,并作为其第一个参数;
5. 如果传入errback的错误不是一个Failure对象,那将会被自动包装一次。