Python+Pika+RabbitMQ环境部署及实现工作队列的实例教程
rabbitmq中文翻译的话,主要还是mq字母上:Message Queue,即消息队列的意思。前面还有个rabbit单词,就是兔子的意思,和python语言叫python一样,老外还是蛮幽默的。rabbitmq服务类似于mysql、apache服务,只是提供的功能不一样。rabbimq是用来提供发送消息的服务,可以用在不同的应用程序之间进行通信。
安装rabbitmq
先来安装下rabbitmq,在ubuntu 12.04下可以直接通过apt-get安装:
sudo apt-get install rabbitmq-server
安装好后,rabbitmq服务就已经启动好了。接下来看下python编写Hello World!的实例。实例的内容就是从send.py发送“Hello World!”到rabbitmq,receive.py从rabbitmq接收send.py发送的信息。
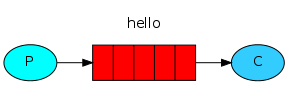
其中P表示produce,生产者的意思,也可以称为发送者,实例中表现为send.py;C表示consumer,消费者的意思,也可以称为接收者,实例中表现为receive.py;中间红色的表示队列的意思,实例中表现为hello队列。
python使用rabbitmq服务,可以使用现成的类库pika、txAMQP或者py-amqplib,这里选择了pika。
安装pika
安装pika可以使用pip来进行安装,pip是python的软件管理包,如果没有安装,可以通过apt-get安装
sudo apt-get install python-pip
通过pip安装pika:
sudo pip install pika
send.py代码
连接到rabbitmq服务器,因为是在本地测试,所以就用localhost就可以了。
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
声明消息队列,消息将在这个队列中进行传递。如果将消息发送到不存在的队列,rabbitmq将会自动清除这些消息。
channel.queue_declare(queue='hello')
发送消息到上面声明的hello队列,其中exchange表示交换器,能精确指定消息应该发送到哪个队列,routing_key设置为队列的名称,body就是发送的内容,具体发送细节暂时先不关注。
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
关闭连接
connection.close()
完整代码
#!/usr/bin/env python
#coding=utf8
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
print " [x] Sent 'Hello World!'"
connection.close()
先来执行下这个程序,执行成功的话,rabbitmqctl应该成功增加了hello队列,并且队列里应该有一条信息,用rabbitmqctl命令来查看下
rabbitmqctl list_queues
在笔者的电脑上输出如下信息:
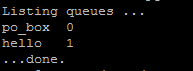
确实有一个hello队列,并且队列里有一条信息。接下来用receive.py来获取队列里的信息。
receive.py代码
和send.py的前面两个步骤一样,都是要先连接服务器,然后声明消息的队列,这里就不再贴同样代码了。
接收消息更为复杂一些,需要定义一个回调函数来处理,这边的回调函数就是将信息打印出来。
def callback(ch, method, properties, body): print "Received %r" % (body,)
告诉rabbitmq使用callback来接收信息
channel.basic_consume(callback, queue='hello', no_ack=True)
开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理。按ctrl+c退出。
channel.start_consuming()
完整代码
#!/usr/bin/env python
#coding=utf8
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
channel.basic_consume(callback, queue='hello', no_ack=True)
print ' [*] Waiting for messages. To exit press CTRL+C'
channel.start_consuming()
执行程序,就能够接收到队列hello里的消息Hello World!,然后打印在屏幕上。换一个终端,再次执行send.py,可以看到receive.py这边会再次接收到信息。
工作队列示例
1.准备工作(Preparation)
在实例程序中,用new_task.py来模拟任务分配者, worker.py来模拟工作者。
修改send.py,从命令行参数里接收信息,并发送
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print " [x] Sent %r" % (message,)
修改receive.py的回调函数。
import time
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
这边先打开两个终端,都运行worker.py,处于监听状态,这边就相当于两个工作者。打开第三个终端,运行new_task.py
$ python new_task.py First message. $ python new_task.py Second message.. $ python new_task.py Third message... $ python new_task.py Fourth message.... $ python new_task.py Fifth message.....
$ python worker.py [*] Waiting for messages. To exit press CTRL+C [x] Received 'First message.' [x] Received 'Third message...' [x] Received 'Fifth message.....'
另外一个工作者接收到2个任务 :
$ python worker.py [*] Waiting for messages. To exit press CTRL+C [x] Received 'Second message..' [x] Received 'Fourth message....'
从上面来看,每个工作者,都会依次分配到任务。那么如果一个工作者,在处理任务的时候挂掉,这个任务就没有完成,应当交由其他工作者处理。所以应当有一种机制,当一个工作者完成任务时,会反馈消息。
2.消息确认(Message acknowledgment)
消息确认就是当工作者完成任务后,会反馈给rabbitmq。修改worker.py中的回调函数:
def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep(5) print " [x] Done" ch.basic_ack(delivery_tag = method.delivery_tag)
这边停顿5秒,可以方便ctrl+c退出。
去除no_ack=True参数或者设置为False也可以。
channel.basic_consume(callback, queue='hello', no_ack=False)
用这个代码运行,即使其中一个工作者ctrl+c退出后,正在执行的任务也不会丢失,rabbitmq会将任务重新分配给其他工作者。
3.消息持久化存储(Message durability)
虽然有了消息反馈机制,但是如果rabbitmq自身挂掉的话,那么任务还是会丢失。所以需要将任务持久化存储起来。声明持久化存储:
channel.queue_declare(queue='hello', durable=True)
但是这个程序会执行错误,因为hello这个队列已经存在,并且是非持久化的,rabbitmq不允许使用不同的参数来重新定义存在的队列。重新定义一个队列:
channel.queue_declare(queue='task_queue', durable=True)
在发送任务的时候,用delivery_mode=2来标记任务为持久化存储:
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
4.公平调度(Fair dispatch)
上面实例中,虽然每个工作者是依次分配到任务,但是每个任务不一定一样。可能有的任务比较重,执行时间比较久;有的任务比较轻,执行时间比较短。如果能公平调度就最好了,使用basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务,即只有工作者完成任务之后,才会再次接收到任务。
channel.basic_qos(prefetch_count=1)
new_task.py完整代码
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print " [x] Sent %r" % (message,)
connection.close()
worker.py完整代码
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
