简单谈谈python中的Queue与多进程
最近接触一个项目,要在多个虚拟机中运行任务,参考别人之前项目的代码,采用了多进程来处理,于是上网查了查python中的多进程
一、先说说Queue(队列对象)
Queue是python中的标准库,可以直接import 引用,之前学习的时候有听过著名的“先吃先拉”与“后吃先吐”,其实就是这里说的队列,队列的构造的时候可以定义它的容量,别吃撑了,吃多了,就会报错,构造的时候不写或者写个小于1的数则表示无限多
import Queue
q = Queue.Queue(10)
向队列中放值(put)
q.put(‘yang')
q.put(4)
q.put([‘yan','xing'])
在队列中取值get()
默认的队列是先进先出的
>>> q.get()
‘yang'
>>> q.get()
4
>>> q.get()
[‘yan', ‘xing']
当一个队列为空的时候如果再用get取则会堵塞,所以取队列的时候一般是用到
get_nowait()方法,这种方法在向一个空队列取值的时候会抛一个Empty异常
所以更常用的方法是先判断一个队列是否为空,如果不为空则取值
队列中常用的方法
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 获取队列,timeout等待时间
Queue.get_nowait() 相当Queue.get(False)
非阻塞 Queue.put(item) 写入队列,timeout等待时间
Queue.put_nowait(item) 相当Queue.put(item, False)
二、multiprocessing中使用子进程概念
from multiprocessing import Process
可以通过Process来构造一个子进程
p = Process(target=fun,args=(args))
再通过p.start()来启动子进程
再通过p.join()方法来使得子进程运行结束后再执行父进程
from multiprocessing import Process
import os
# 子进程要执行的代码
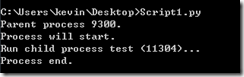
def run_proc(name):
print 'Run child process %s (%s)...' % (name, os.getpid())
if __name__=='__main__':
print 'Parent process %s.' % os.getpid()
p = Process(target=run_proc, args=('test',))
print 'Process will start.'
p.start()
p.join()
print 'Process end.'
三、在multiprocessing中使用pool
如果需要多个子进程时可以考虑使用进程池(pool)来管理
from multiprocessing import Pool
from multiprocessing import Pool import os, time def long_time_task(name): print 'Run task %s (%s)...' % (name, os.getpid()) start = time.time() time.sleep(3) end = time.time() print 'Task %s runs %0.2f seconds.' % (name, (end - start)) if __name__=='__main__': print 'Parent process %s.' % os.getpid() p = Pool() for i in range(5): p.apply_async(long_time_task, args=(i,)) print 'Waiting for all subprocesses done...' p.close() p.join() print 'All subprocesses done.'
pool创建子进程的方法与Process不同,是通过
p.apply_async(func,args=(args))实现,一个池子里能同时运行的任务是取决你电脑的cpu数量,如我的电脑现在是有4个cpu,那会子进程task0,task1,task2,task3可以同时启动,task4则在之前的一个某个进程结束后才开始
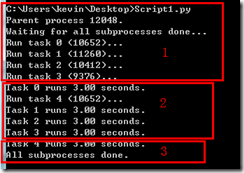
上面的程序运行后的结果其实是按照上图中1,2,3分开进行的,先打印1,3秒后打印2,再3秒后打印3
代码中的p.close()是关掉进程池子,是不再向里面添加进程了,对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
当时也可以是实例pool的时候给它定义一个进程的多少
如果上面的代码中p=Pool(5)那么所有的子进程就可以同时进行
三、多个子进程间的通信
多个子进程间的通信就要采用第一步中说到的Queue,比如有以下的需求,一个子进程向队列中写数据,另外一个进程从队列中取数据,
#coding:gbk from multiprocessing import Process, Queue import os, time, random # 写数据进程执行的代码: def write(q): for value in ['A', 'B', 'C']: print 'Put %s to queue...' % value q.put(value) time.sleep(random.random()) # 读数据进程执行的代码: def read(q): while True: if not q.empty(): value = q.get(True) print 'Get %s from queue.' % value time.sleep(random.random()) else: break if __name__=='__main__': # 父进程创建Queue,并传给各个子进程: q = Queue() pw = Process(target=write, args=(q,)) pr = Process(target=read, args=(q,)) # 启动子进程pw,写入: pw.start() # 等待pw结束: pw.join() # 启动子进程pr,读取: pr.start() pr.join() # pr进程里是死循环,无法等待其结束,只能强行终止: print print '所有数据都写入并且读完'
四、关于上面代码的几个有趣的问题
if __name__=='__main__': # 父进程创建Queue,并传给各个子进程: q = Queue() p = Pool() pw = p.apply_async(write,args=(q,)) pr = p.apply_async(read,args=(q,)) p.close() p.join() print print '所有数据都写入并且读完'
如果main函数写成上面的样本,本来我想要的是将会得到一个队列,将其作为参数传入进程池子里的每个子进程,但是却得到
RuntimeError: Queue objects should only be shared between processes through inheritance
的错误,查了下,大意是队列对象不能在父进程与子进程间通信,这个如果想要使用进程池中使用队列则要使用multiprocess的Manager类
if __name__=='__main__': manager = multiprocessing.Manager() # 父进程创建Queue,并传给各个子进程: q = manager.Queue() p = Pool() pw = p.apply_async(write,args=(q,)) time.sleep(0.5) pr = p.apply_async(read,args=(q,)) p.close() p.join() print print '所有数据都写入并且读完'
这样这个队列对象就可以在父进程与子进程间通信,不用池则不需要Manager,以后再扩展multiprocess中的Manager类吧
关于锁的应用,在不同程序间如果有同时对同一个队列操作的时候,为了避免错误,可以在某个函数操作队列的时候给它加把锁,这样在同一个时间内则只能有一个子进程对队列进行操作,锁也要在manager对象中的锁
#coding:gbk from multiprocessing import Process,Queue,Pool import multiprocessing import os, time, random # 写数据进程执行的代码: def write(q,lock): lock.acquire() #加上锁 for value in ['A', 'B', 'C']: print 'Put %s to queue...' % value q.put(value) lock.release() #释放锁 # 读数据进程执行的代码: def read(q): while True: if not q.empty(): value = q.get(False) print 'Get %s from queue.' % value time.sleep(random.random()) else: break if __name__=='__main__': manager = multiprocessing.Manager() # 父进程创建Queue,并传给各个子进程: q = manager.Queue() lock = manager.Lock() #初始化一把锁 p = Pool() pw = p.apply_async(write,args=(q,lock)) pr = p.apply_async(read,args=(q,)) p.close() p.join() print print '所有数据都写入并且读完'