【Python】Python的urllib模块、urllib2模块批量进行网页下载文件
由于需要从某个网页上下载一些PDF文件,但是需要下载的PDF文件有几百个,所以不可能用人工点击来下载。正好Python有相关的模块,所以写了个程序来进行PDF文件的下载,顺便熟悉了Python的urllib模块和ulrllib2模块。
1、问题描述
需要从http://www.cvpapers.com/cvpr2014.html上下载几百个论文的PDF文件,该网页如下图所示: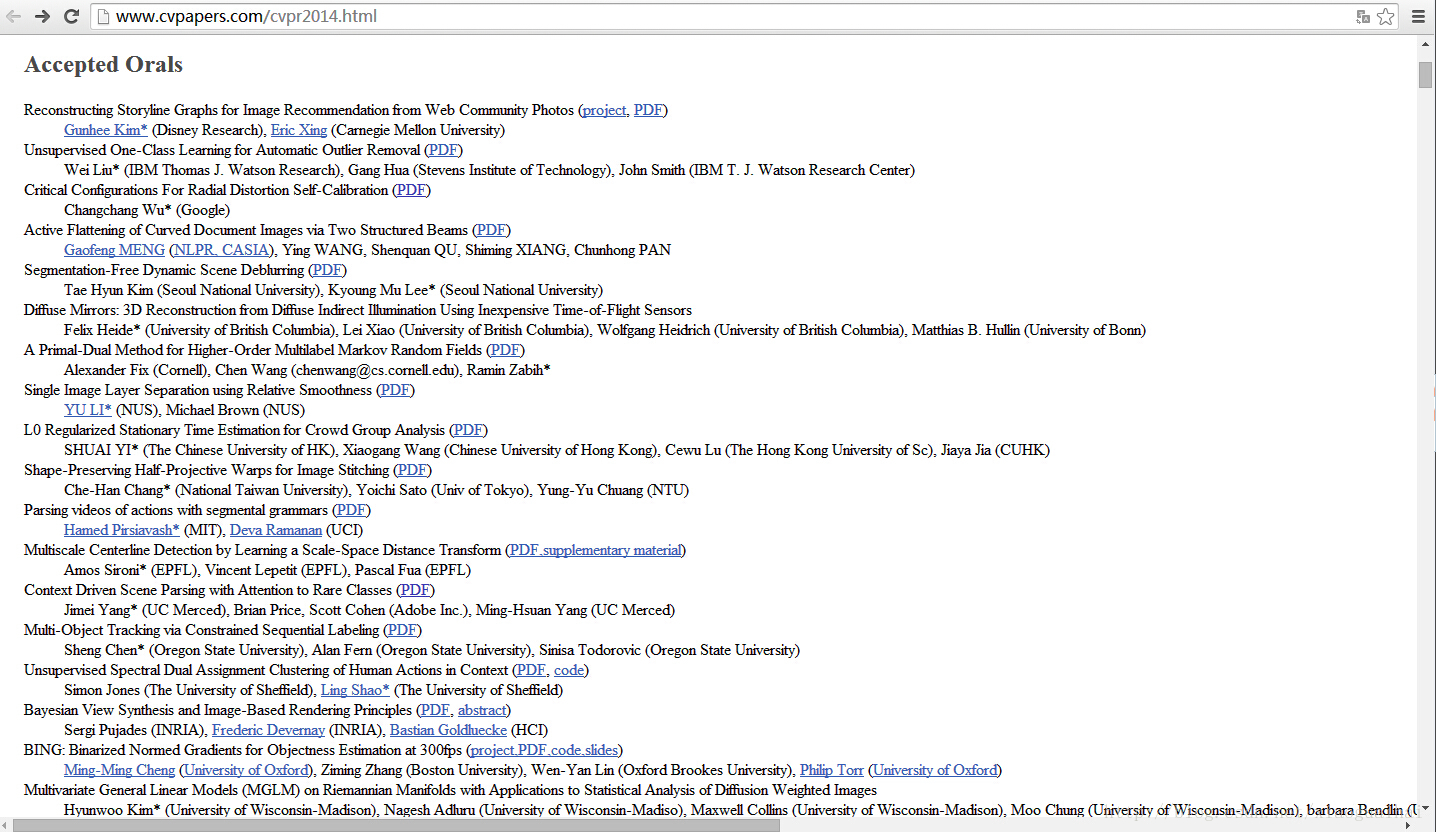
2、问题解决
通过结合Python的urllib模块和urllib2模块来实现自动下载。代码如下:
test.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
import urllib #导入urllib模块
import urllib2 #导入urllib2模块
import re #导入正则表达式模块:re模块
def getPDFFromNet(inputURL):
req = urllib2.Request(inputURL)
f = urllib2.urlopen(req) #打开网页
localDir = 'E:\downloadPDF\\' #下载PDF文件需要存储在本地的文件夹
urlList = [] #用来存储提取的PDF下载的url的列表
for eachLine in f: #遍历网页的每一行
line = eachLine.strip() #去除行首位的空格,习惯性写法
if re.match('.*PDF.*', line): #去匹配含有“PDF”字符串的行,只有这些行才有PDF下载地址
wordList = line.split('\"') #以"为分界,将该行分开,这样就将url地址单独分开了
for word in wordList: #遍历每个字符串
if re.match('.*\.pdf$', word): #去匹配含有“.pdf”的字符串,只有url中才有
urlList.append(word) #将提取的url存入列表
for everyURL in urlList: #遍历列表的每一项,即每一个PDF的url
wordItems = everyURL.split('/') #将url以/为界进行划分,为了提取该PDF文件名
for item in wordItems: #遍历每个字符串
if re.match('.*\.pdf$', item): #查找PDF的文件名
PDFName = item #查找到PDF文件名
localPDF = localDir + PDFName #将本地存储目录和需要提取的PDF文件名进行连接
try:
urllib.urlretrieve(everyURL, localPDF) #按照url进行下载,并以其文件名存储到本地目录
except Exception,e:
continue
getPDFFromNet('http://www.cvpapers.com/cvpr2014.html')
注意:
(1)第1、6、8、23行分别多谢了一个“\”来进行转义;
(2)第27行的urlretrieve函数有3个参数:第一个参数就是目标url;第二个参数是保存的文件绝对路径(含文件名),该函数的返回值是一个tuple(filename,header),其中的filename就是第二个参数filename。如果urlretrieve仅提供1个参数,返回值的filename就是产生的临时文件名,函数执行完毕后该临时文件会被删除参数。第3个参数是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。其中回调函数名称可任意,但是参数必须为三个。一般直接使用reporthook(block_read,block_size,total_size)定义回调函数,block_size是每次读取的数据块的大小,block_read是每次读取的数据块个数,taotal_size是一一共读取的数据量,单位是byte。可以使用reporthook函数来显示读取进度。
如果想显示读取进度,则可以讲第三个参数加上,将上述程序第27行改为如下:
urllib.urlretrieve(everyURL, localPDF, reporthook=reporthook)
而reporthook回调函数的代码如下:
def reporthook(block_read,block_size,total_size): if not block_read: print "connection opened"; return if total_size<0: #unknown size print "read %d blocks (%dbytes)" %(block_read,block_read*block_size); else: amount_read=block_read*block_size; print 'Read %d blocks,or %d/%d' %(block_read,block_read*block_size,total_size);
综上所述,这就是一个简单的从网页抓取数据、下载文件的小程序,希望对正在学习Python的同学有帮助。谢谢!