python模块之re正则表达式详解
一、简单介绍
正则表达式是一种小型的、高度专业化的编程语言,并不是python中特有的,是许多编程语言中基础而又重要的一部分。在python中,主要通过re模块来实现。
正则表达式模式被编译成一系列的字节码,然后由用c编写的匹配引擎执行。那么正则表达式通常有哪些使用场景呢?
比如为想要匹配的相应字符串集指定规则;
该字符串集可以是包含e-mail地址、Internet地址、电话号码,或是根据需求自定义的一些字符串集;
当然也可以去判断一个字符串集是否符合我们定义的匹配规则;
找到字符串中匹配该规则的部分内容;
修改、切割等一系列的文本处理;
......
二、特殊符号和字符(元字符)
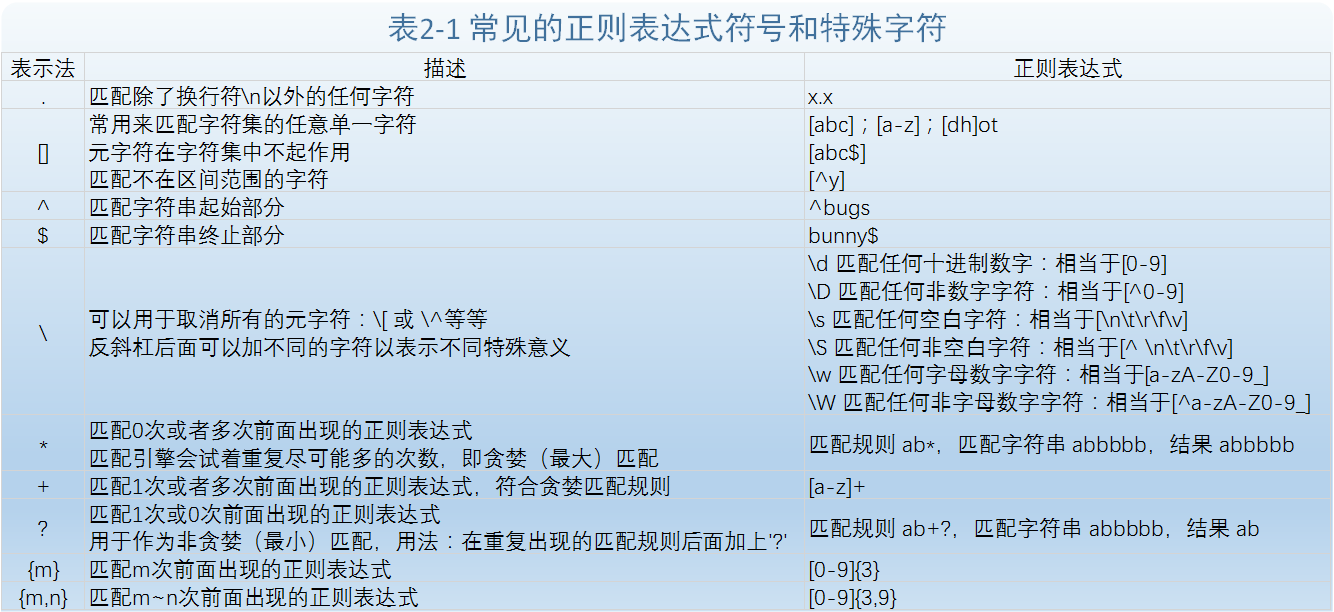
这里介绍常见的一些元字符,它给予正则表达式强大的功能和灵活性。表2-1列出了比较常见的符号和字符。
三、正则表达式
1、使用 compile()函数编译正则表达式
由于python代码最终会被翻译成字节码,然后在解释器上执行。所以对于我们代码中经常要用到的一些正则表达式进行预编译,执行起来会更加便捷。
re模块中的大多数函数和已经编译的正则表达式对象和正则匹配对象的方法同名并且具有相同的功能。
示例:
>>> import re
>>> r1 = r'bugs' # 字符串前加"r"反斜杠就不会被任何特殊方式处理,这是个习惯,虽然这里没用到
>>> re.findall(r1, 'bugsbunny') # 直接利用re模块进行解释性地匹配
['bugs']
>>>
>>> r2 = re.compile(r1) # 如果r1这个匹配规则你会经常用到,为了提高效率,那就进行预编译吧
>>> r2 # 编译后的正则对象
<_sre.SRE_Pattern object at 0x7f5d7db99bb0>
>>>
>>> r2.findall('bugsbunny') # 访问对象的findall方法得到的匹配结果与上面是一致的
['bugs'] # 所以说,re模块中的大多数函数和已经编译的正则表达式对象和正则匹配对象的方法同名并且具有相同的功能
re.compile()函数也接受可选的标志参数,常用来实现不同的特殊功能和语法变更。这些标志也可以作为参数适用于大多数re模块函数。这些标志可以用操作法(|)合并。
示例:
>>> import re
>>> r1 = r'bugs'
>>> r2 = re.compile(r1,re.I) # 这里选择的是忽略大小写的标志,完整的是re.IGNORECASE,这里简写re.I
>>> r2.findall('BugsBunny')
['Bugs']<br><br># re.S 使.匹配换行符在内的所有字符<br># re.M 多行匹配,英雄^和$<br># re,X 用来使正则匹配模式组织得更加清晰
完整的标志参数列表和用法可以参考相关官方文档。
2、使用正则表达式
re模块提供了一个正则表达式引擎的接口,下面具体介绍一些常用的函数和方法。
匹配对象以及group()和groups()方法
当处理正则表达式时,除了正则表达式对象之外,还有一个对象类型:匹配对象。这些是成功调用 match()或者search()返回的对象。匹配对象有两个主要的方法:group()和groups()。
group()要么返回整个匹配对象,要么根据要求返回特定子组。groups()则仅返回一个包含唯一或者全部子组的元组。如果没有子组的要求,那么当group()仍然返回整个匹配时,groups返回一个空元组。下面一些函数示例会演示到此方法。
使用 match()方法匹配字符串
match()函数从字符串的起始部分对模式进行匹配。如果匹配成功,就返回一个匹配对象;如果匹配失败,就返回 None,匹配对象的方法 group()方法就能够用于显示那个成功的匹配。
示例如下:
>>> m = re.match('bugs', 'bugsbunny') # 模式匹配字符串
>>> if m is not None: # 如果匹配成功,就输出匹配内容
... m.group()
...
'bugs'<br>>>> m<br><_sre.SRE_Match object at 0x7f5d7da1f168> # 确认返回的匹配对象
使用search()在一个字符串中查找模式
search()的工作方式与match()完全一致,不同之处在于search()是对给定正则表达式模式搜索第一次出现的匹配情况。简单来说,就是在任意位置符合都能匹配成功,不仅仅是字符串的起始部分,这就是与match()函数的区别,用脚指头想想search()方法使用的范围更多更广。
示例:
>>> m = re.search('bugs', 'hello bugsbunny')
>>> if m is not None:
... m.group()
...
'bugs'
使用findall()和finditer()查找每一次出现的位置
findall()是用来查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表;finditer()与findall()不同的地方是返回一个迭代器,对于每一次匹配,迭代器都返回一个匹配对象。
>>> m = re.findall('bugs', 'bugsbunnybugs')
>>> m
['bugs', 'bugs']
>>> m = re.finditer('bugs', 'bugsbunnybugs')
>>> m.next() # 迭代器用next()方法返回一个匹配对象
<_sre.SRE_Match object at 0x7f5d7da71a58> # 匹配用group()方法显示出来
>>> m.next().group()
'bugs'
使用sub()和subn()搜索与替换
都是将某字符串中所有匹配正则表达式的部分进行某种形式的替换。sub()返回一个用来替换的字符串,可以定义替换次数,默认替换所有出现的位置。subn()和sub()一样,但subn()还返回一个表示替换的总是,替换后的字符串和表示替换总数一起作为一个拥有两个元素的元组返回。
示例:
>>> r = 'a.b'
>>> m = 'acb abc aab aac'
>>> re.sub(r,'hello',m)
'hello abc hello aac'<br>>>> re.subn(r,'hello',m)<br>('hello abc hello aac', 2)
字符串也有一个replace()方法,当遇到一些模糊搜索替换的时候,就需要更为灵活的sub()方法了。
使用split()分割字符串
同样的,字符串中也有split(),但它也不能处理正则表达式匹配的分割。在re模块中,分居正则表达式的模式分隔符,split函数将字符串分割为列表,然后返回成功匹配的列表。
示例:
>>> s = '1+2-3*4' >>> re.split(r'[\+\-\*]',s) ['1', '2', '3', '4']
分组
有时在匹配的时候我们只想提取一些想要的信息或者对提取的信息作一个分类,这时就需要对正则匹配模式进行分组,只需要加上()即可。
示例:
>>> m = re.match('(\w{3})-(\d{3})','abc-123')
>>> m.group() # 完整匹配
'abc-123'
>>> m.group(1) # 子组1
'abc'
>>> m.group(2) # 子组2
'123'
>>> m.groups() # 全部子组
('abc', '123')
由以上的例子可以看出,group()通常用于以普通方式显示所有的匹配部分,但也能用于获取各个匹配的子组。可以使用groups()方法来获取一个包含所有匹配字符串的元组。
以上所述是小编给大家介绍的python模块之re正则表达式详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!