Python实现多线程HTTP下载器示例
本文将介绍使用Python编写多线程HTTP下载器,并生成.exe可执行文件。
环境:windows/Linux + Python2.7.x
单线程
在介绍多线程之前首先介绍单线程。编写单线程的思路为:
1.解析url;
2.连接web服务器;
3.构造http请求包;
4.下载文件。
接下来通过代码进行说明。
解析url
通过用户输入url进行解析。如果解析的路径为空,则赋值为'/';如果端口号为空,则赋值为"80”;下载文件的文件名可根据用户的意愿进行更改(输入'y'表示更改,输入其它表示不需要更改)。
下面列出几个解析函数:
#解析host和path
def analyHostAndPath(totalUrl):
protocol,s1 = urllib.splittype(totalUrl)
host, path = urllib.splithost(s1)
if path == '':
path = '/'
return host, path
#解析port
def analysisPort(host):
host, port = urllib.splitport(host)
if port is None:
return 80
return port
#解析filename
def analysisFilename(path):
filename = path.split('/')[-1]
if '.' not in filename:
return None
return filename
连接web服务器
使用socket模块,根据解析url得到的host和port连接web服务器,代码如下:
import socket from analysisUrl import port,host ip = socket.gethostbyname(host) s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect((ip, port)) print "success connected webServer!!"
构造http请求包
根据解析url得到的path, host, port构造一个HTTP请求包。
from analysisUrl import path, host, port packet = 'GET ' + path + ' HTTP/1.1\r\nHost: ' + host + '\r\n\r\n'
下载文件
根据构造的http请求包,向服务器发送文件,抓取响应报文头部的"Content-Length"。
def getLength(self):
s.send(packet)
print "send success!"
buf = s.recv(1024)
print buf
p = re.compile(r'Content-Length: (\d*)')
length = int(p.findall(buf)[0])
return length, buf
下载文件并计算下载所用的时间。
def download(self):
file = open(self.filename,'wb')
length,buf = self.getLength()
packetIndex = buf.index('\r\n\r\n')
buf = buf[packetIndex+4:]
file.write(buf)
sum = len(buf)
while 1:
buf = s.recv(1024)
file.write(buf)
sum = sum + len(buf)
if sum >= length:
break
print "Success!!"
if __name__ == "__main__":
start = time.time()
down = downloader()
down.download()
end = time.time()
print "The time spent on this program is %f s"%(end - start)
多线程
抓取响应报文头部的"Content-Length"字段,结合线程个数,加锁分段下载。与单线程的不同,这里将所有代码整合为一个文件,代码中使用更多的Python自带模块。
得到"Content-Length":
def getLength(self):
opener = urllib2.build_opener()
req = opener.open(self.url)
meta = req.info()
length = int(meta.getheaders("Content-Length")[0])
return length
根据得到的Length,结合线程个数划分范围:
def get_range(self):
ranges = []
length = self.getLength()
offset = int(int(length) / self.threadNum)
for i in range(self.threadNum):
if i == (self.threadNum - 1):
ranges.append((i*offset,''))
else:
ranges.append((i*offset,(i+1)*offset))
return ranges
实现多线程下载,在向文件写入内容时,向线程加锁,并使用with lock代替lock.acquire( )...lock.release( );使用file.seek( )设置文件偏移地址,保证写入文件的准确性。
def downloadThread(self,start,end):
req = urllib2.Request(self.url)
req.headers['Range'] = 'bytes=%s-%s' % (start, end)
f = urllib2.urlopen(req)
offset = start
buffer = 1024
while 1:
block = f.read(buffer)
if not block:
break
with lock:
self.file.seek(offset)
self.file.write(block)
offset = offset + len(block)
def download(self):
filename = self.getFilename()
self.file = open(filename, 'wb')
thread_list = []
n = 1
for ran in self.get_range():
start, end = ran
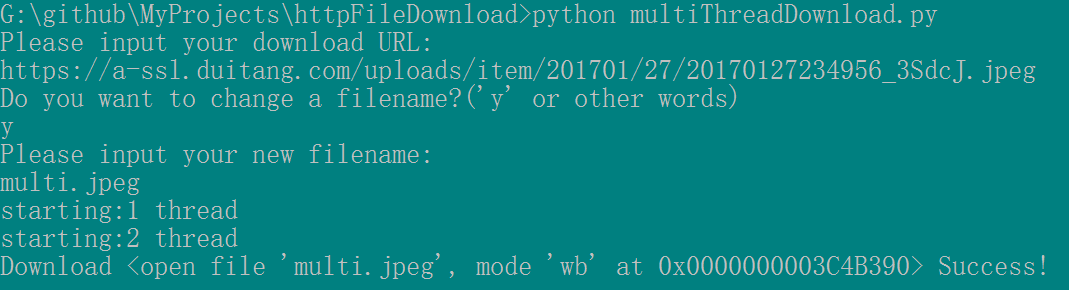
print 'starting:%d thread '% n
n += 1
thread = threading.Thread(target=self.downloadThread,args=(start,end))
thread.start()
thread_list.append(thread)
for i in thread_list:
i.join()
print 'Download %s Success!'%(self.file)
self.file.close()
运行结果:
将(*.py)文件转化为(*.exe)可执行文件
当写好了一个工具,如何让那些没有安装Python的人使用这个工具呢?这就需要将.py文件转化为.exe文件。
这里用到Python的py2exe模块,初次使用,所以对其进行介绍:
py2exe是一个将Python脚本转换成windows上可独立执行的可执行文件(*.exe)的工具,这样,就可以不用装Python在windows上运行这个可执行程序。
接下来,在multiThreadDownload.py的同目录下,创建mysetup.py文件,编写:
from distutils.core import setup import py2exe setup(console=["multiThreadDownload.py"])
接着执行命令:Python mysetup.py py2exe
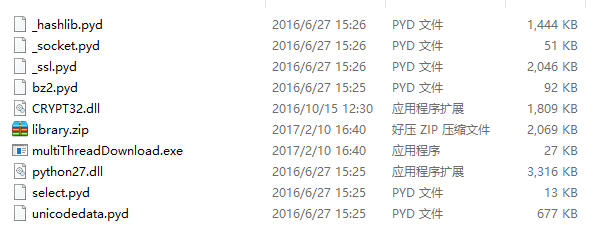
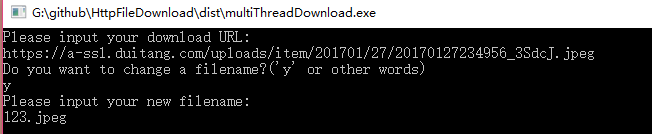
生成dist文件夹,multiTjhreadDownload.exe文件位于其中,点击运行即可:
demo下载地址:HttpFileDownload_jb51.rar
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。