python检查URL是否正常访问的小技巧
今天,项目经理问我一个问题,问我这里有2000个URL要检查是否能正常打开,其实我是拒绝的,我知道因为要写代码了,正好学了点Python,一想,python处理起来容易,就选了python,开始把思路想好:
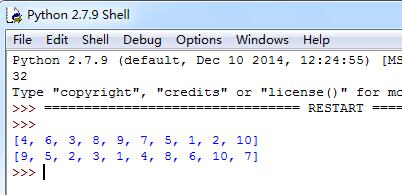
1.首先2000个URL。可以放在一个txt文本内
2.通过python 把内容内的URL一条一条放进数组内
3.打开一个模拟的浏览器,进行访问。
4.如果正常访问就输出正常,错误就输出错误
直接简单粗暴甩代码。因为涉及到隐私,图片打了码
import urllib.request
import time
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/49.0.2')]
#这个是你放网址的文件名,改过来就可以了
file = open('test.txt')
lines = file.readlines()
aa=[]
for line in lines:
temp=line.replace('\n','')
aa.append(temp)
print(aa)
print('开始检查:')
for a in aa:
tempUrl = a
try :
opener.open(tempUrl)
print(tempUrl+'没问题')
except urllib.error.HTTPError:
print(tempUrl+'=访问页面出错')
time.sleep(2)
except urllib.error.URLError:
print(tempUrl+'=访问页面出错')
time.sleep(2)
time.sleep(0.1)
效果图:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。