python实现稀疏矩阵示例代码
工程实践中,多数情况下,大矩阵一般都为稀疏矩阵,所以如何处理稀疏矩阵在实际中就非常重要。本文以Python里中的实现为例,首先来探讨一下稀疏矩阵是如何存储表示的。
1.sparse模块初探
python中scipy模块中,有一个模块叫sparse模块,就是专门为了解决稀疏矩阵而生。本文的大部分内容,其实就是基于sparse模块而来的。
第一步自然就是导入sparse模块
>>> from scipy import sparse
然后help一把,先来看个大概
>>> help(sparse)
直接找到我们最关心的部分:
Usage information
=================
There are seven available sparse matrix types:
1. csc_matrix: Compressed Sparse Column format
2. csr_matrix: Compressed Sparse Row format
3. bsr_matrix: Block Sparse Row format
4. lil_matrix: List of Lists format
5. dok_matrix: Dictionary of Keys format
6. coo_matrix: COOrdinate format (aka IJV, triplet format)
7. dia_matrix: DIAgonal format
To construct a matrix efficiently, use either dok_matrix or lil_matrix.
The lil_matrix class supports basic slicing and fancy
indexing with a similar syntax to NumPy arrays. As illustrated below,
the COO format may also be used to efficiently construct matrices.
To perform manipulations such as multiplication or inversion, first
convert the matrix to either CSC or CSR format. The lil_matrix format is
row-based, so conversion to CSR is efficient, whereas conversion to CSC
is less so.
All conversions among the CSR, CSC, and COO formats are efficient,
linear-time operations.
通过这段描述,我们对sparse模块就有了个大致的了解。sparse模块里面有7种存储稀疏矩阵的方式。接下来,我们对这7种方式来做个一一介绍。
2.coo_matrix
coo_matrix是最简单的存储方式。采用三个数组row、col和data保存非零元素的信息。这三个数组的长度相同,row保存元素的行,col保存元素的列,data保存元素的值。一般来说,coo_matrix主要用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改等操作,一旦矩阵创建成功以后,会转化为其他形式的矩阵。
>>> row = [2,2,3,2] >>> col = [3,4,2,3] >>> c = sparse.coo_matrix((data,(row,col)),shape=(5,6)) >>> print c.toarray() [[0 0 0 0 0 0] [0 0 0 0 0 0] [0 0 0 5 2 0] [0 0 3 0 0 0] [0 0 0 0 0 0]]
稍微需要注意的一点是,用coo_matrix创建矩阵的时候,相同的行列坐标可以出现多次。矩阵被真正创建完成以后,相应的坐标值会加起来得到最终的结果。
3.dok_matrix与lil_matrix
dok_matrix和lil_matrix适用的场景是逐渐添加矩阵的元素。doc_matrix的策略是采用字典来记录矩阵中不为0的元素。自然,字典的key存的是记录元素的位置信息的元祖,value是记录元素的具体值。
>>> import numpy as np >>> from scipy.sparse import dok_matrix >>> S = dok_matrix((5, 5), dtype=np.float32) >>> for i in range(5): ... for j in range(5): ... S[i, j] = i + j ... >>> print S.toarray() [[ 0. 1. 2. 3. 4.] [ 1. 2. 3. 4. 5.] [ 2. 3. 4. 5. 6.] [ 3. 4. 5. 6. 7.] [ 4. 5. 6. 7. 8.]]
lil_matrix则是使用两个列表存储非0元素。data保存每行中的非零元素,rows保存非零元素所在的列。这种格式也很适合逐个添加元素,并且能快速获取行相关的数据。
>>> from scipy.sparse import lil_matrix >>> l = lil_matrix((6,5)) >>> l[2,3] = 1 >>> l[3,4] = 2 >>> l[3,2] = 3 >>> print l.toarray() [[ 0. 0. 0. 0. 0.] [ 0. 0. 0. 0. 0.] [ 0. 0. 0. 1. 0.] [ 0. 0. 3. 0. 2.] [ 0. 0. 0. 0. 0.] [ 0. 0. 0. 0. 0.]] >>> print l.data [[] [] [1.0] [3.0, 2.0] [] []] >>> print l.rows [[] [] [3] [2, 4] [] []]
由上面的分析很容易可以看出,上面两种构建稀疏矩阵的方式,一般也是用来通过逐渐添加非零元素的方式来构建矩阵,然后转换成其他可以快速计算的矩阵存储方式。
4.dia_matrix
这是一种对角线的存储方式。其中,列代表对角线,行代表行。如果对角线上的元素全为0,则省略。
如果原始矩阵是个对角性很好的矩阵那压缩率会非常高。
找了网络上的一张图,大家就很容易能看明白其中的原理。

5.csr_matrix与csc_matrix
csr_matrix,全名为Compressed Sparse Row,是按行对矩阵进行压缩的。CSR需要三类数据:数值,列号,以及行偏移量。CSR是一种编码的方式,其中,数值与列号的含义,与coo里是一致的。行偏移表示某一行的第一个元素在values里面的起始偏移位置。
同样在网络上找了一张图,能比较好反映其中的原理。
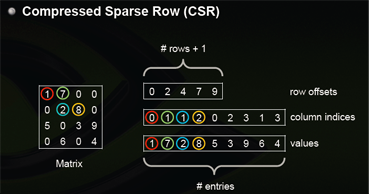
看看在python里怎么使用:
>>> from scipy.sparse import csr_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
怎么样,是不是也不是很难理解。
我们再看看文档中是怎么说的
Notes | ----- | | Sparse matrices can be used in arithmetic operations: they support | addition, subtraction, multiplication, division, and matrix power. | | Advantages of the CSR format | - efficient arithmetic operations CSR + CSR, CSR * CSR, etc. | - efficient row slicing | - fast matrix vector products | | Disadvantages of the CSR format | - slow column slicing operations (consider CSC) | - changes to the sparsity structure are expensive (consider LIL or DOK)
不难看出,csr_matrix比较适合用来做真正的矩阵运算。
至于csc_matrix,跟csr_matrix类似,只不过是基于列的方式压缩的,不再单独介绍。
6.bsr_matrix
Block Sparse Row format,顾名思义,是按分块的思想对矩阵进行压缩。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。