使用Python实现博客上进行自动翻页
先上一张代码及代码运行后的输出结果的图!

下面上代码:
# coding=utf-8
import os
import time
from selenium import webdriver
#打开火狐浏览器 需要V47版本以上的
driver = webdriver.Firefox()#打开火狐浏览器
url = "http://codelife.ecit-it.com"#这里打开我的博客网站
driver.get(url)#设置火狐浏览器打开的网址
time.sleep(2)
#使用xpath进行多路径或多元素定位,用法看官网http://selenium-python.readthedocs.io/locating-elements.html
elem_dh = driver.find_elements_by_xpath("//div[@class='pagination pagination-large']/ul/li/a")
print ("我是刚获取的翻页按钮的路径数组:",elem_dh)
print ("下一页按钮元素:",elem_dh[2])
time.sleep(5)
#获取当前窗口句柄
now_handle = driver.current_window_handle #获取当前窗口句柄
print ("我是当前窗口的句柄:",now_handle)#打印窗口句柄 是一串数字
time.sleep(10)
#循环获取界面
for elem in elem_dh:
print ("我是翻页按钮上的文本信息:",elem.text) #获取元素的文本值
print ("我是翻页按钮的地址",elem.get_attribute('href')) #获取元素的href属性值
elem.click()#点击进入新的界面 _blank弹出
print ("刚翻页完成了!")
time.sleep(20)
代码为了让大家能看清楚是怎么回事,代码我已经加了注解。
运行上面的代码后执行的结果如下:
>>> 我是刚获取的翻页按钮的路径数组: [<selenium.webdriver.firefox.webelement.FirefoxWebElement (session="b4375c0c-a3b7-42b9-aa73-ed513699718e", element="782b0162-44eb-4710-bbeb-fc4402ec7cdc")>, <selenium.webdriver.firefox.webelement.FirefoxWebElement (session="b4375c0c-a3b7-42b9-aa73-ed513699718e", element="40e0eede-4ecb-4d95-850f-aa3e6b18e360")>, <selenium.webdriver.firefox.webelement.FirefoxWebElement (session="b4375c0c-a3b7-42b9-aa73-ed513699718e", element="2665129e-ce82-4018-bfe4-a8a6ac300a19")>] 我是当前窗口的句柄: 2147483652 我是翻页按钮上的文本信息: « 上一页 我是翻页按钮的地址 None 刚翻页完成了! 我是翻页按钮上的文本信息: 2 我是翻页按钮的地址 http://codelife.ecit-it.com/page2 刚翻页完成了! 我是翻页按钮上的文本信息: 下一页 » 我是翻页按钮的地址 http://codelife.ecit-it.com/page2 刚翻页完成了!
很多同学会问运行中是个什么情况,给大家上几张图片:
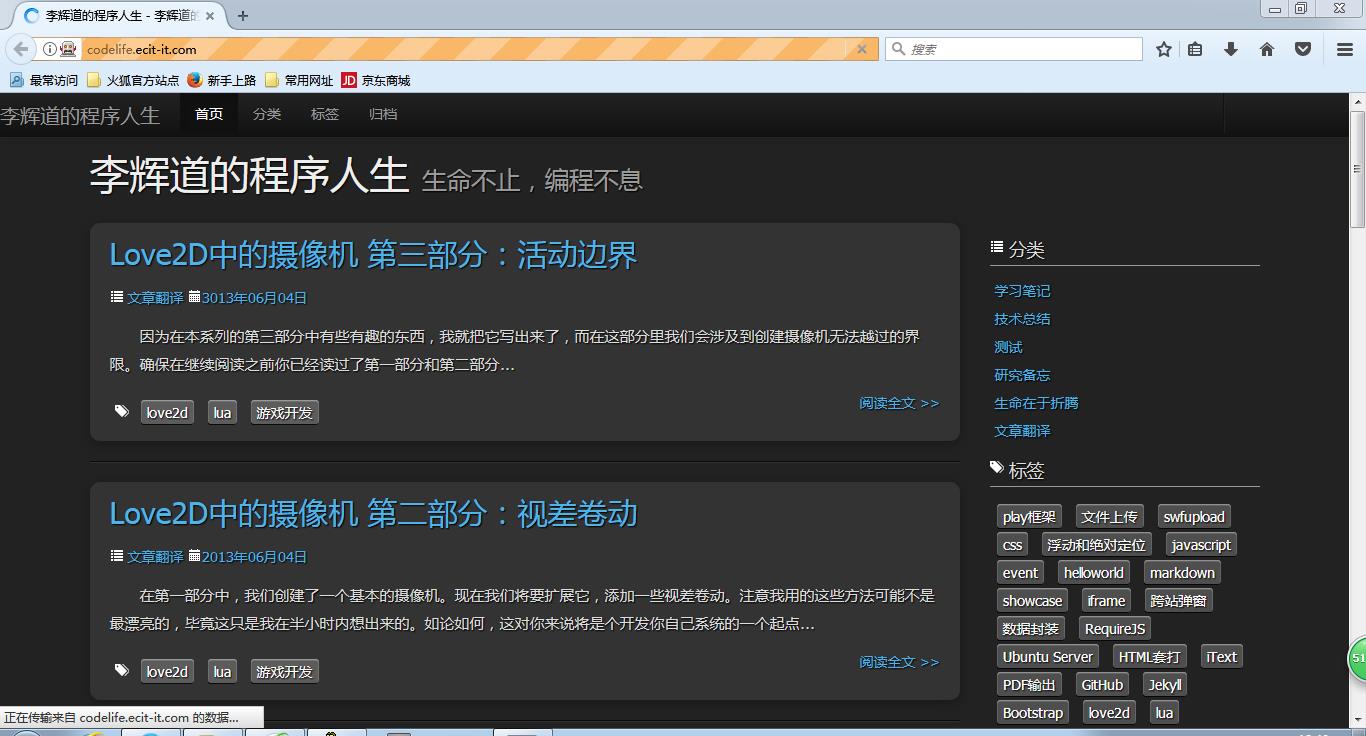
上图是自动在地址栏输入http:codelife.ecit-it.com,并加载博客站点。
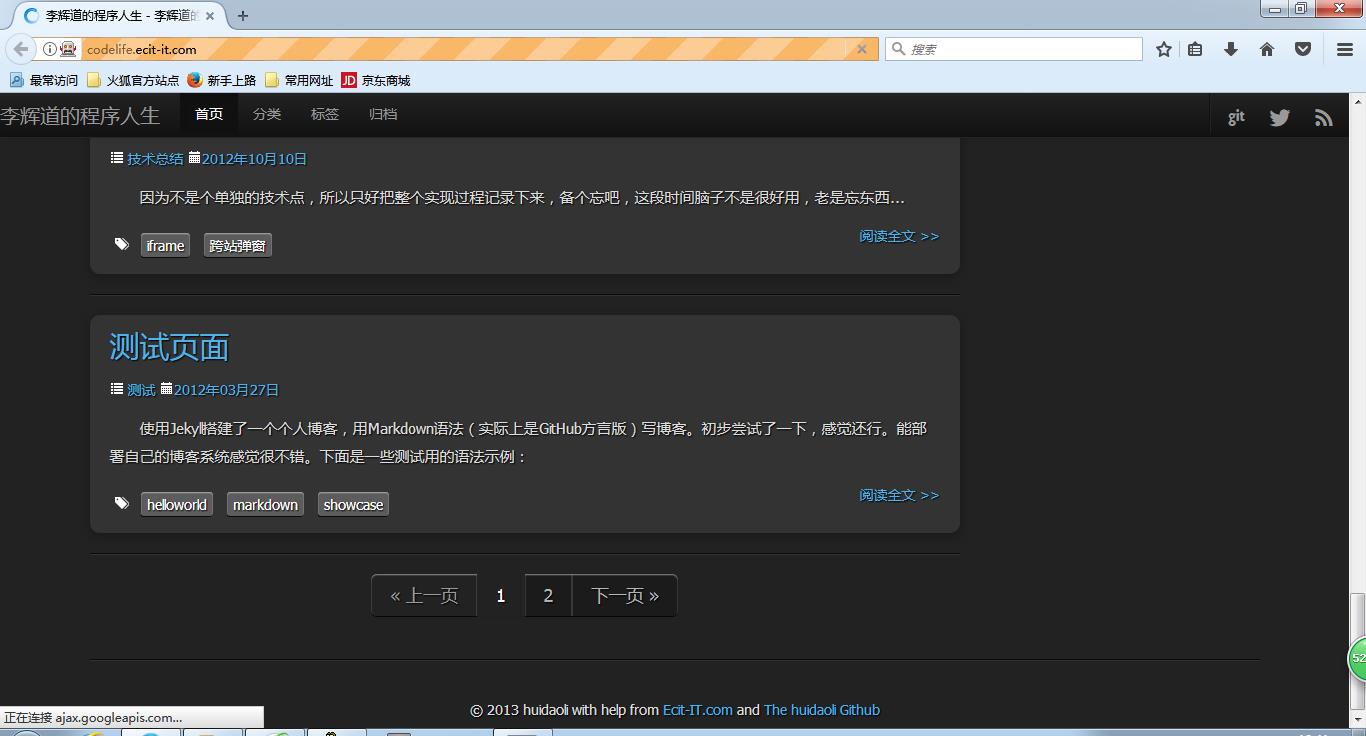
默认加载的是博客第一页的内容哦。

经过等待,等待的过程中千万别走神,否则会错过了哦!上图已经点击了,还好我眼疾手快截到图了。
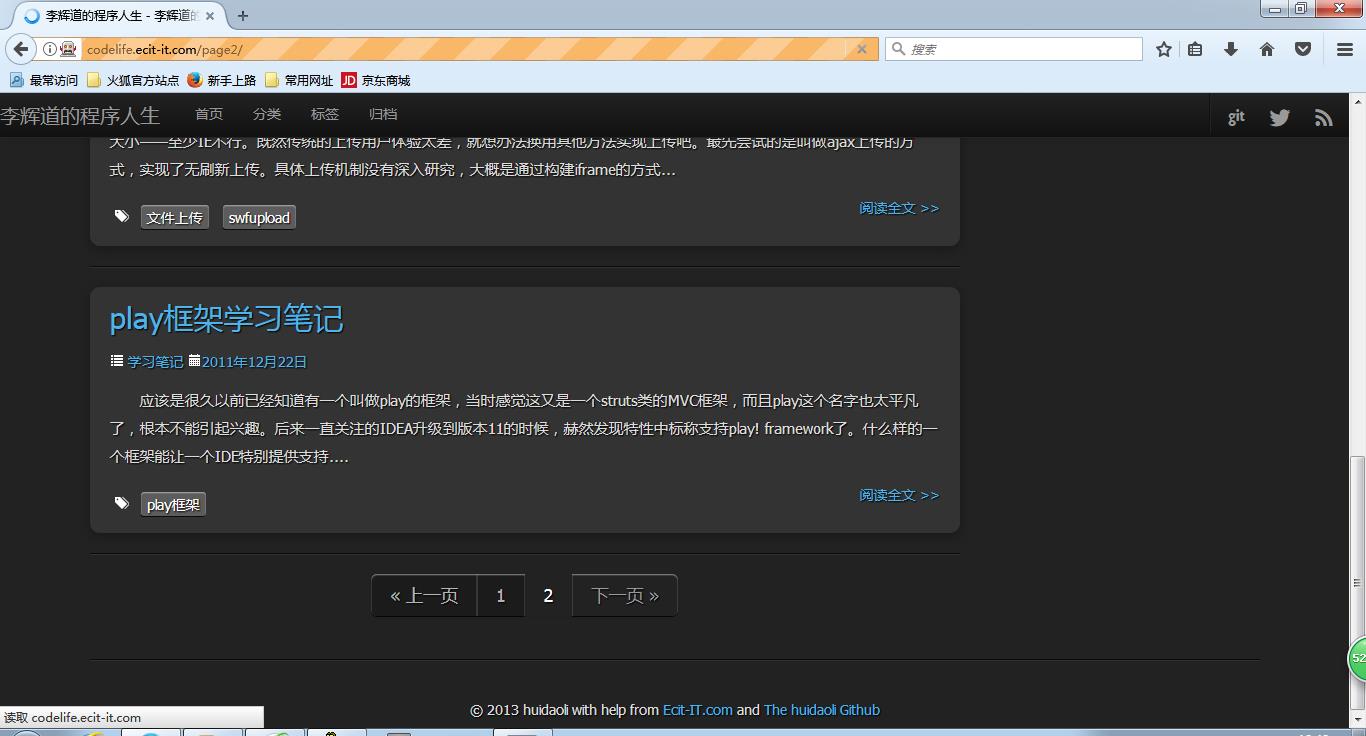
点击完第二页后就跳转到第二页去了。
观察仔细的同学会发现,我后面有一行代码是后来加上去的。
print ("下一页按钮元素:",elem_dh[2])
加入上面一行代码将可以打印出博客上的”下一页“按钮元素的定位数据。
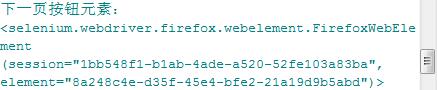
我们可以看到,下一页的元素信息打印出来了。如果有同学需要只点击”下一页“按钮进行翻页的话,可以用到这个元素数组。
关于元素的定位官网有详细的用法,在此不详细介绍,自备楼梯http://selenium-python.readthedocs.io/locating-elements.html
当然,开发环境大家一写要安装完好,安装的插件比较多,如果上面代码大家进行出错的话,说明大家的开发环境有问题,或是少插件,或是版本号与插件不对应。
本人电脑上的Python版本是3.6.2,安装的pywin32也是3.6版本的。
今天就写到这了,后面再继续跟大家分享,一起进步。