python django使用haystack:全文检索的框架(实例讲解)
haystack:全文检索的框架
whoosh:纯Python编写的全文搜索引擎
jieba:一款免费的中文分词包
首先安装这三个包
pip install django-haystack
pip install whoosh
pip install jieba
1.修改settings.py文件,安装应用haystack,
2.在settings.py文件中配置搜索引擎
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
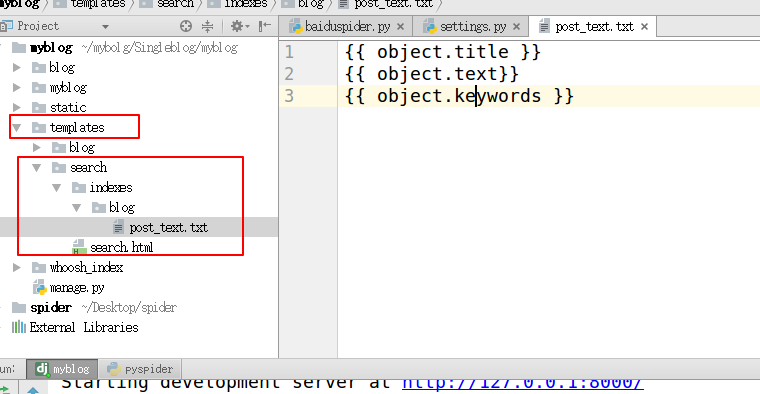
3. 在templates目录下创建“search/indexes/blog/”目录 采用blog应用名字下面创建一个文件blog_text.txt
#指定索引的属性
{{ object.title }}
{{ object.text}}
{{ object.keywords }}
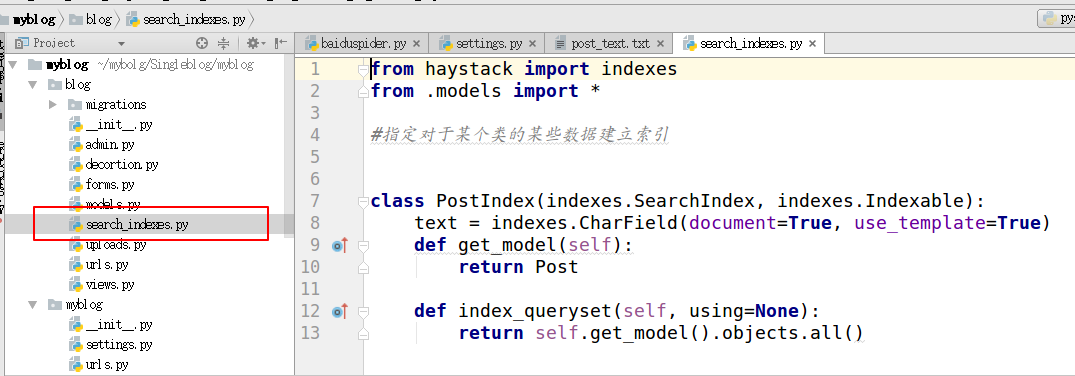
4.在需要搜索的应用下面创建search_indexes
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
5.
1. 修改haystack文件
2. 找到虚拟环境py_django下的haystack目录 这个目录根据自己使用的python环境不同,路径也不一样。
3. site-packages/haystack/backends/ 创建一个文件名为ChineseAnalyzer.py文件写入下面代码,用于中文分词
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
6.
1. 复制whoosh_backend.py文件,改为如下名称
whoosh_cn_backend.py
在复制出来的文件中导入中文分词模块
from .ChineseAnalyzer import ChineseAnalyzer
2. 更改词语分析类 改成中文
查找analyzer=StemmingAnalyzer()改为analyzer=ChineseAnalyzer()
7. 最后一步就是建初始化索引数据
python manage.py rebuild_index
8. 创建搜索模板 在templates/indexes/ 创建search.html模板
搜索结果进行分页,视图向模板中传递的上下文如下
query:搜索关键字
page:当前页的page对象
paginator:分页paginator对象
9. 在自己的应用视图中导入模块
from haystack.generic_views import SearchView
定义一个类重写get_context_data 方法,这样就可以往模板中传递自定义的上下文。
class GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return context
应用的urls文件中添加这条url 将类当一个视图的方法使用 .as_view()
url('^search/$', views.BlogSearchView.as_view())
以上这篇python django使用haystack:全文检索的框架(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。