Python scikit-learn 做线性回归的示例代码
一、概述
机器学习算法在近几年大数据点燃的热火熏陶下已经变得被人所“熟知”,就算不懂得其中各算法理论,叫你喊上一两个著名算法的名字,你也能昂首挺胸脱口而出。当然了,算法之林虽大,但能者还是有限,能适应某些环境并取得较好效果的算法会脱颖而出,而表现平平者则被历史所淡忘。随着机器学习社区的发展和实践验证,这群脱颖而出者也逐渐被人所认可和青睐,同时获得了更多社区力量的支持、改进和推广。
以最广泛的分类算法为例,大致可以分为线性和非线性两大派别。线性算法有著名的逻辑回归、朴素贝叶斯、最大熵等,非线性算法有随机森林、决策树、神经网络、核机器等等。线性算法举的大旗是训练和预测的效率比较高,但最终效果对特征的依赖程度较高,需要数据在特征层面上是线性可分的。因此,使用线性算法需要在特征工程上下不少功夫,尽量对特征进行选择、变换或者组合等使得特征具有区分性。而非线性算法则牛逼点,可以建模复杂的分类面,从而能更好的拟合数据。
那在我们选择了特征的基础上,哪个机器学习算法能取得更好的效果呢?谁也不知道。实践是检验哪个好的不二标准。那难道要苦逼到写五六个机器学习的代码吗?No,机器学习社区的力量是强大的,码农界的共识是不重复造轮子!因此,对某些较为成熟的算法,总有某些优秀的库可以直接使用,省去了大伙调研的大部分时间。
基于目前使用python较多,而python界中远近闻名的机器学习库要数scikit-learn莫属了。这个库优点很多。简单易用,接口抽象得非常好,而且文档支持实在感人。本文中,我们可以封装其中的很多机器学习算法,然后进行一次性测试,从而便于分析取优。当然了,针对具体算法,超参调优也非常重要。
二、Scikit-learn的python实践
本篇文章利用线性回归算法预测波士顿的房价。波士顿房价数据集包含波士顿郊区住房价值的信息。
第一步:Python库导入
%matplotlib inline import numpy as np import pandas as pd import matplotlib.pyplot as plt import sklearn
第二步:数据获取和理解
波士顿数据集是scikit-learn的内置数据集,可以直接拿来使用。
from sklearn.datasets import load_boston boston = load_boston()
print(boston.keys())
dict_keys([‘data', ‘target', ‘feature_names', ‘DESCR'])
print(boston.data.shape)
(506, 13)
print(boston.feature_names)
[‘CRIM' ‘ZN' ‘INDUS' ‘CHAS' ‘NOX' ‘RM' ‘AGE' ‘DIS' ‘RAD' ‘TAX' ‘PTRATIO''B' ‘LSTAT']
结论:波士顿数据集506个样本,14个特征。
print(boston.DESCR)
bos = pd.DataFrame(boston.data) print(bos.head())
0 1 2 3 4 5 6 7 8 9 10 \
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7
11 12
0 396.90 4.98
1 396.90 9.14
2 392.83 4.03
3 394.63 2.94
4 396.90 5.33
bos.columns = boston.feature_names print(bos.head())
print(boston.target[:5])
bos['PRICE'] = boston.target
bos.head()
第三步:数据模型构建——线性回归
from sklearn.linear_model import LinearRegression
X = bos.drop('PRICE', axis=1)
lm = LinearRegression()
lm
lm.fit(X, bos.PRICE)
print('线性回归算法w值:', lm.coef_)
print('线性回归算法b值: ', lm.intercept_)
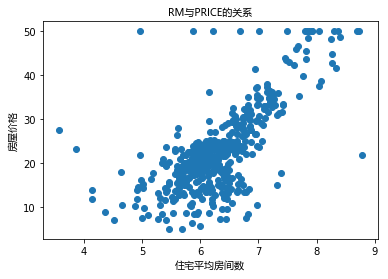
import matplotlib.font_manager as fm myfont = fm.FontProperties(fname='C:/Windows/Fonts/msyh.ttc') plt.scatter(bos.RM, bos.PRICE) plt.xlabel(u'住宅平均房间数', fontproperties=myfont) plt.ylabel(u'房屋价格', fontproperties=myfont) plt.title(u'RM与PRICE的关系', fontproperties=myfont) plt.show()
第四步:数据模型应用——预测房价
lm.predict(X)[0:5]
array([ 30.00821269, 25.0298606 , 30.5702317 , 28.60814055, 27.94288232])
mse = np.mean((bos.PRICE - lm.predict(X)) ** 2) print(mse)
21.897779217687486
总结
1 使用.DESCR探索波士顿数据集,业务目标是预测波士顿郊区住房的房价;
2 使用scikit-learn针对整个数据集拟合线性回归模型,并计算均方误差。
思考环节
1 对数据集分割成训练数据集和测试数据集
2 训练数据集训练线性回归模型,利用线性回归模型对测试数据集进行预测
3 计算训练模型的MSE和测试数据集预测结果的MSE
4 绘制测试数据集的残差图
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。