浅谈Python处理PDF的方法
处理pdf文档
第一、
从文本中提取文本

第二、
创建PDF
两种方法
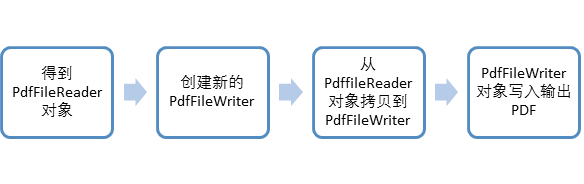
#使用PdfFileWriter
import PyPDF2
pdfFiles = []
for filename in os.listdir('.'):
if filename.endswith('.pdf'):
pdfFiles.append(filename)
print(pdfFiles)
pdfWriter = PyPDF2.PdfFileWriter()
pdfFileObj = open(pdfFiles[0],'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj) # 得到PdfFileReader对象
first,end =map(int,input('从多少页到多少页(用空格隔开):').split())
for pageNum in range(first-1,end):
pageObj = pdfReader.getPage(pageNum)
pdfWriter.addPage(pageObj)
pdfOutput = open ('split_pdf.pdf','wb')
pdfWriter.write(pdfOutput)
pdfOutput.close()

#使用PdfFileMerger()
import PyPDF2
merger = PyPDF2.PdfFileMerger()
a = [str(i)+'webbook.pdf'for i in range(0,124)]
for i in a:
print(i)
merger.append(open(i,'rb'))
print("合并完成第"+str(i))
with open('combintion.pdf','wb') as f:
merger.write(f)
总结
以上就是本文关于浅谈Python处理PDF的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:python先序遍历二叉树问题、python实现人脸识别代码、python执行使用shell命令方法分享等,有什么问题可以随时留言,小编会及时回复大家的。感谢朋友们对本站的支持!