python实现二叉树的遍历
本文实例为大家分享了python实现二叉树的遍历具体代码,供大家参考,具体内容如下
代码:
# -*- coding: gb2312 -*-
class Queue(object):
def __init__(self):
self.q = []
def enqueue(self, item):
self.q.append(item)
def dequeue(self):
# if self.q != []:
if len(self.q)>0:
return self.q.pop(0)
else:
return None
def length(self):
return len(self.q)
def isempty(self):
return len(self.q)==0
class Stack(object):
def __init__(self):
self.s = []
def push(self, item):
self.s.append(item)
def pop(self):
if self.s !=[]:
item = self.s.pop(-1)
else:
item = None
return item
def length(self):
return len(self.s)
def isempty(self):
return self.s == []
def top(self):
return self.s[-1]
class TreeNode(object):
def __init__(self, data, left=None, right=None):
self.data = data
self.left = left
self.right = right
self.visited = False
def setData(self, data):
self.data = data
def setLeft(self, left):
self.left = left
def setRight(self, right):
self.right = right
def visit(self):
print self.data,
self.visited = True
def deVisit(self):
self.visited = False
class BinaryTree(object):
def __init__(self, root):
self.root = root
# 前序遍历(递归)
def freshVisit(self, node):
if node is not None:
node.deVisit()
if node.left:
self.freshVisit(node.left)
if node.right:
self.freshVisit(node.right)
# 前序遍历(递归)
def preOrder(self, node):
if node is not None:
node.visit()
if node.left:
self.preOrder(node.left)
if node.right:
self.preOrder(node.right)
# 中序遍历(递归)
def inOrder(self, node):
if node.left:
self.inOrder(node.left)
if node is not None:
node.visit()
if node.right:
self.inOrder(node.right)
# 后序遍历(递归)
def postOrder(self, node):
if node.left:
self.postOrder(node.left)
if node.right:
self.postOrder(node.right)
if node is not None:
node.visit()
# 递归遍历
def orderTraveral(self, type):
if type == 0:
self.preOrder(self.root)
elif type == 1:
self.inOrder(self.root)
elif type == 2:
self.postOrder(self.root)
# 前序遍历(非递归)
# 用到一个栈和一个队列
# 首先是根节点入栈,再循环出栈
# 出栈元素不为空,则访问
# 出栈元素有左孩子节点则入栈,如果有右孩子节点则入队列
# 出栈元素为空,则访问队列
# 队列也为空则结束循环,否则队列元素出队
# 访问出队元素,出队元素有左孩子节点则入栈,出队元素有右孩子节点则入队列
# 循环直到最后退出
def preOrderByNotRecursion(self):
s = Stack()
q = Queue()
q.enqueue(self.root)
while not s.isempty() or not q.isempty():
if not q.isempty():
item = q.dequeue()
item.visit()
if item.left:
q.enqueue(item.left)
if item.right:
s.push(item.right)
elif not s.isempty():
item = s.pop()
item.visit()
if item.left:
q.enqueue(item.left)
if item.right:
s.push(item.right)
# 前序遍历(非递归)
# 用到一个栈
# 首先是根节点入栈,再循环出栈
# 栈顶元素不为空,则访问, 并置已访问标志
# 如栈顶元素有左孩子节点则入栈
# 若栈顶元素已访问,则出栈
# 出栈元素若有右孩子节点则入栈
# 循环直到栈无元素退出
def preOrderByNotRecursion2(self):
s = Stack()
s.push(self.root)
while not s.isempty():
item = s.top()
if item.visited:
s.pop()
if item.right:
s.push(item.right)
else:
item.visit()
if item.left:
s.push(item.left)
# 中序遍历(非递归)
# 用到一个栈
# 先将根节点入栈,循环出栈
# 如果出栈元素有左孩子节点并且左孩子节点没有访问过则入栈
# 反之,则出栈并且访问;如果出栈元素有右孩子节点则入栈
# 重复以上循环直到栈为空
def inOrderByNotRecursion(self):
s = Stack()
s.push(self.root)
while not s.isempty():
item = s.top()
while(item.left and not item.left.visited):
s.push(item.left)
item = item.left
else:
item = s.pop()
item.visit()
if item.right:
s.push(item.right)
# 后序遍历(非递归)
# 用到一个栈
# 先将根节点入栈,循环出栈
# 如果出栈元素有左孩子节点并且左孩子节点没有访问过则入栈
# 反之,如果栈顶元素如果有右孩子节点并且右孩子节点没有访问过,则入栈
# 否则,出栈并访问
# 重复以上循环直到栈为空
def postOrderByNotRecursion(self):
s = Stack()
s.push(self.root)
while not s.isempty():
item = s.top()
while(item.left and not item.left.visited):
s.push(item.left)
item = item.left
else:
if item.right and not item.right.visited:
s.push(item.right)
else:
item = s.pop()
item.visit()
# 层次遍历(非递归)
# 用到一个队列
# 先将根节点入队列
# 从队列取出一个元素,访问
# 如有左孩子节点则入队,如有右孩子节点则入队
# 重复以上操作直到队列入空
def layerOrder(self):
q = Queue()
q.enqueue(self.root)
while not q.isempty():
item = q.dequeue()
item.visit()
if item.left:
q.enqueue(item.left)
if item.right:
q.enqueue(item.right)
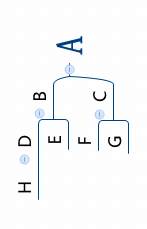
# A
# B C
# D E F G
#H
if __name__ == '__main__':
nE = TreeNode('E');
nF = TreeNode('F');
nG = TreeNode('G');
nH = TreeNode('H');
nD = TreeNode('D', nH);
nB = TreeNode('B', nD, nE);
nC = TreeNode('C', nF, nG);
nA = TreeNode('A', nB, nC);
bTree = BinaryTree(nA);
# 前序递归遍历
print '----------前序遍历(递归)-----------'
bTree.orderTraveral(0)
print '\n----------中序遍历(递归)-----------'
bTree.orderTraveral(1)
print '\n----------后序遍历(递归)-----------'
bTree.orderTraveral(2)
print '\n\n----------前序遍历(非递归)-----------'
print '----------方法一-----------'
bTree.freshVisit(bTree.root)
bTree.preOrderByNotRecursion()
print '\n----------方法二-----------'
bTree.freshVisit(bTree.root)
bTree.preOrderByNotRecursion2()
print '\n\n----------中序遍历(非递归)-----------'
bTree.freshVisit(bTree.root)
bTree.inOrderByNotRecursion()
print '\n\n----------后序遍历(非递归)-----------'
bTree.freshVisit(bTree.root)
bTree.postOrderByNotRecursion()
print '\n\n----------层次遍历(非递归)-----------'
bTree.freshVisit(bTree.root)
bTree.layerOrder()
结果:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。